flowchart TB
A[Function] -- fits --> B[Data]
AI in a Nutshell
This nutshell contains very little math!
Creating Models
fastai
AI models are much, much simpler than you think.
This blog post was updated on Saturday, 12 November 2022.

This article was inspired by the How does a neural net really work Kaggle Notebook by Jeremy Howard, and lesson 3 of Practical Deep Learning for Coders.
Artificial Intelligence. Machine Learning. Neural Networks. Deep Learning. Fancy Words. Deceptively Simple. All really the same.
The basic workflow to create such a system is below.
Very simple, eh? Of course, it’s a very high level abstraction, but this high level view will make this seemingly complex topic very simple.
First, what’s the main thing modern AI methods try to do? They try to make predictions about certain things.
So a function of sorts is needed to achieve this. A function that can make these predictions. Think of a function as a machine. You put something into the machine and then, with whatever was input, the machine then produces an output.
The machine that we will be working with has two input slots: one slot is for training and the other slot is for predictions.
To create a function that produces predictions, we need to tell the function what sort of predictions it needs to make.
To do that, we can pour some data into the training slot. This data will tell the function what sort of predictions to output. This process is known as fitting the function to the data.
To fit the function onto data, you train the function.
Simple Case: Quadratic Function
Gasp! A quadratic?? What’s this nonsense!
A quadratic is a very simple equation. When shown on a graph, it looks like this.
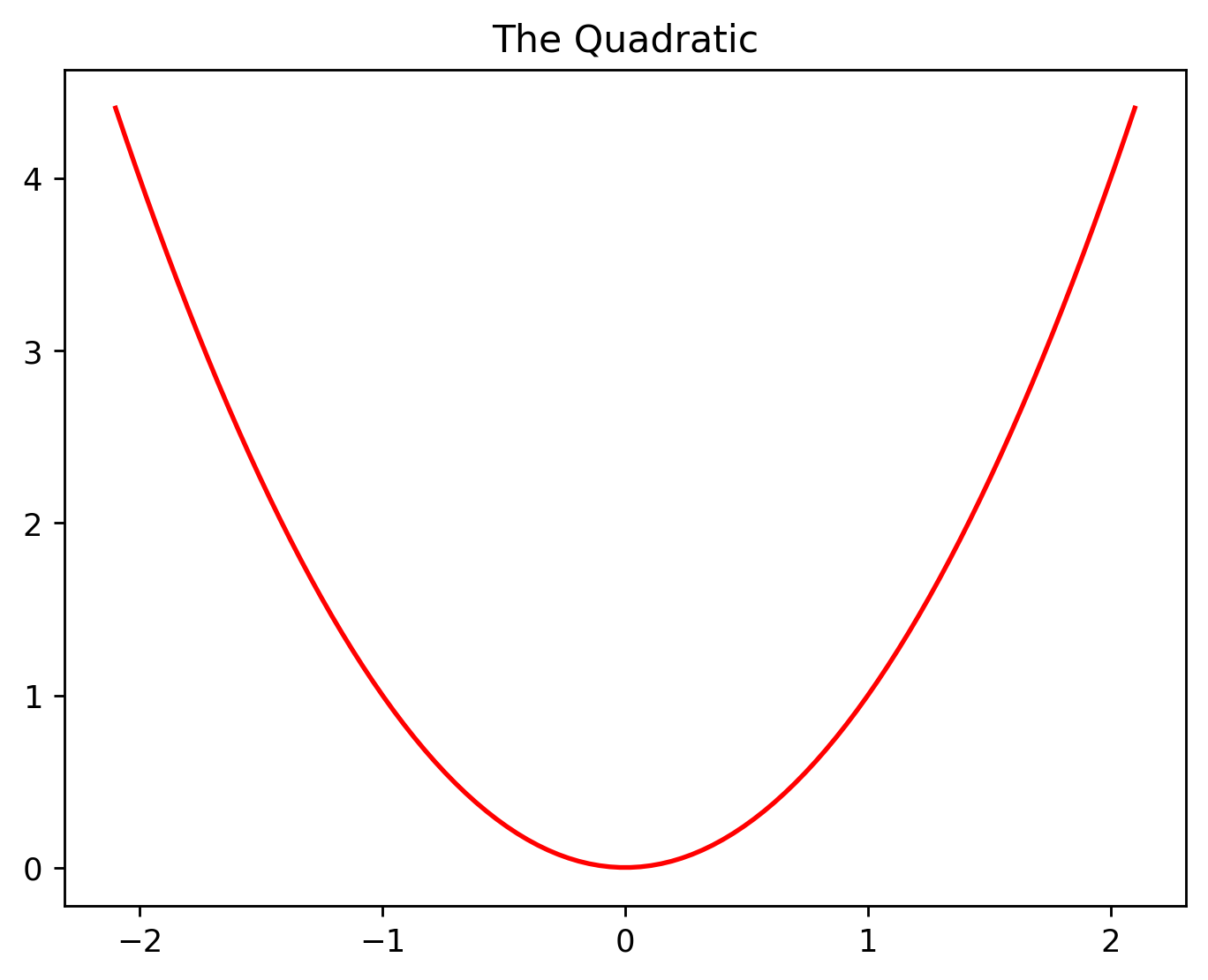
We’ll be using this equation to demonstrate a very simple example.
The basic workflow for fitting a function to data is below.
flowchart TB
B[Calculate Loss] --> C[Calculate Gradients] --> D[Update Parameters] --> B
It can seem like a lot at first glance; quite a few new terms too.
We’ll break this down by going over the very simple example.
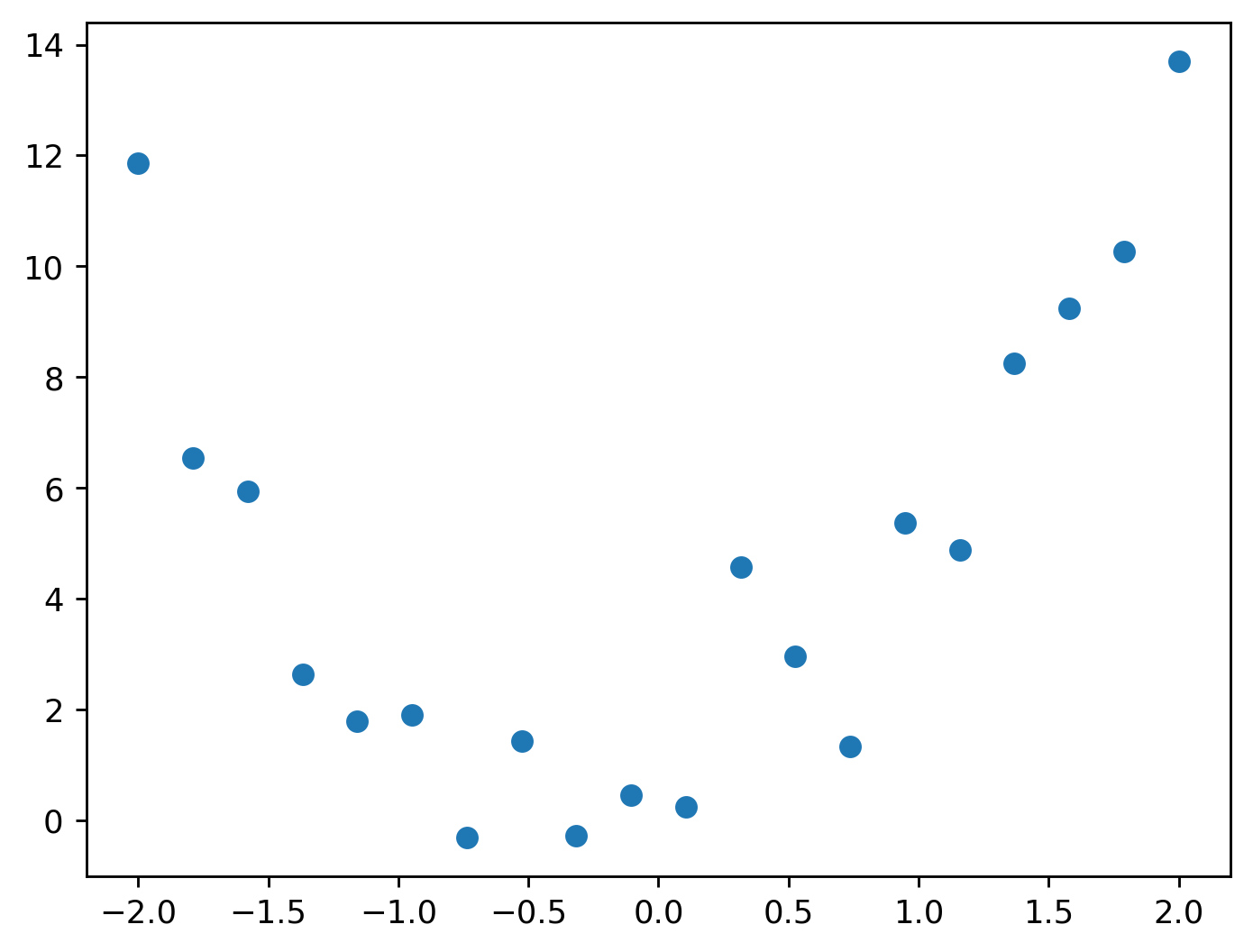
Let’s say we have the following data points that describe, say, the speed of an object with respect to time. We want to predict what the speed of an object would be outside these data points.
The horizontal axis is time and the vertical axis is the object’s speed.
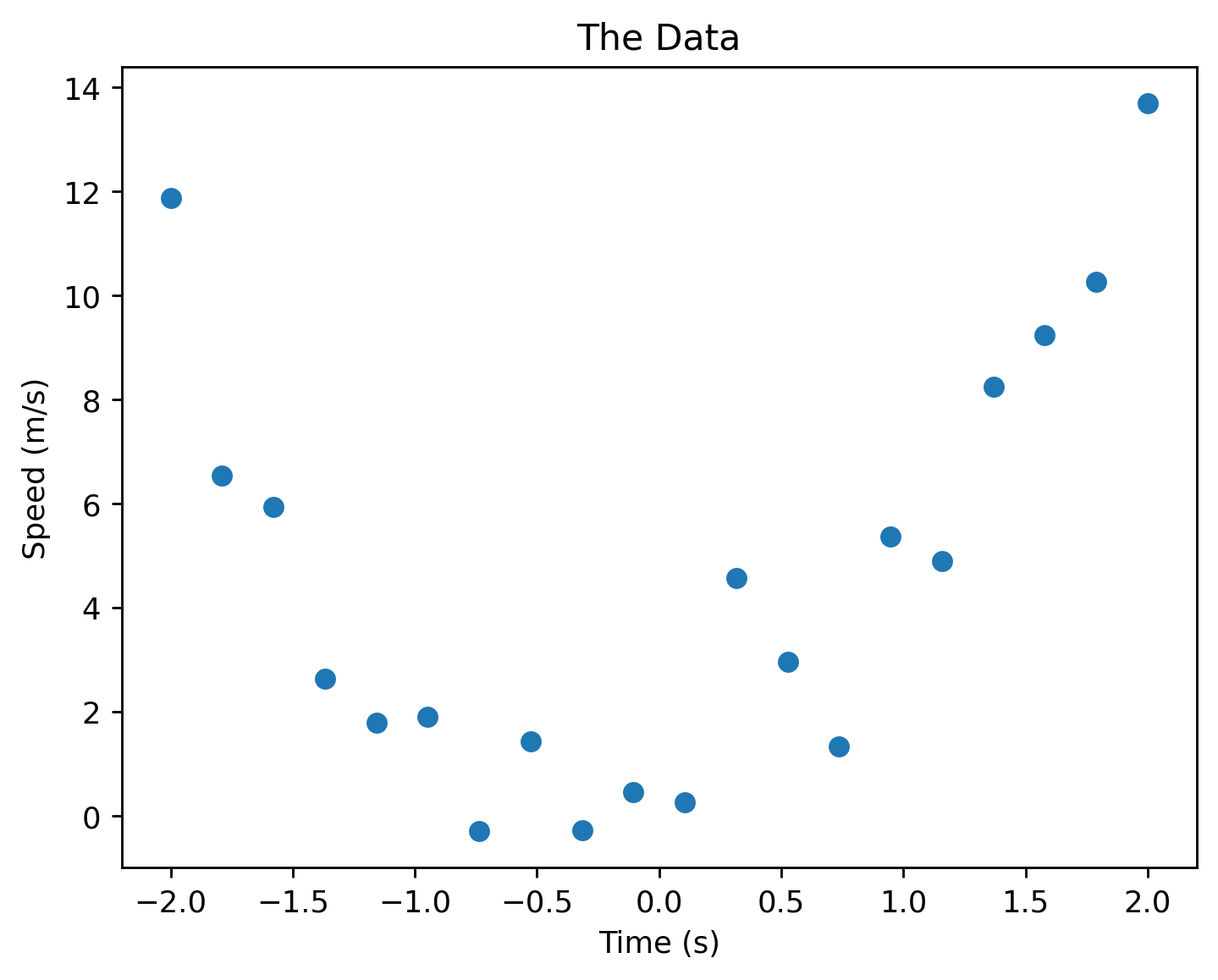
We can see that the data looks like the quadratic function shown above! Therefore, we could use the quadratic to predict what the speed of the object would be after 2.0 s and before -2.0 s.
A quadratic equation includes three numbers which we will call \(a\), \(b\), and \(c\). These three numbers affect or control how our quadratic function will end up looking. \(a\), \(b\), and \(c\) are our parameters.
Let’s let \(a\), \(b\), and \(c\) all equal \(1\) to begin with.
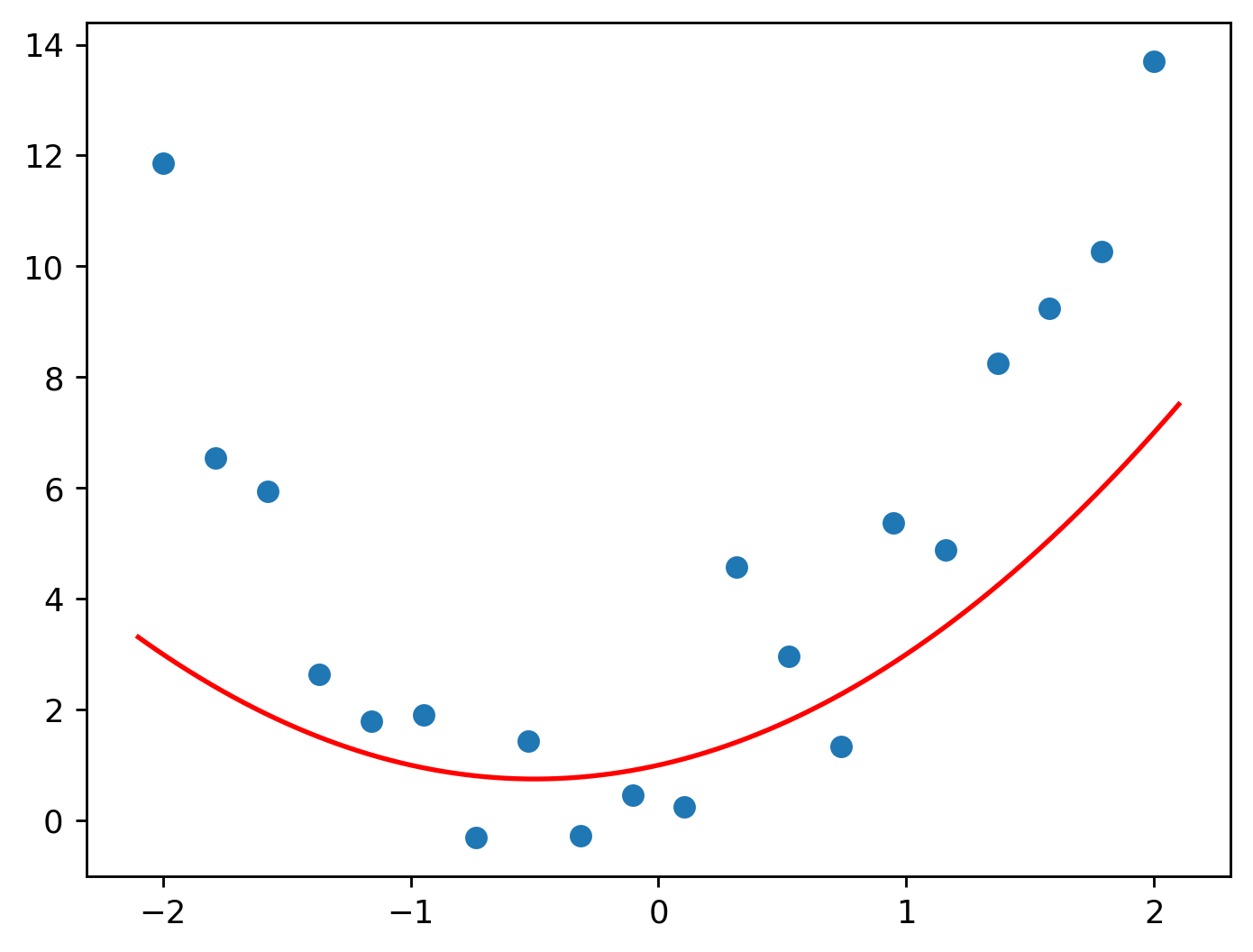
Hmm, not a very good fit.
Let’s try another set of values for the parameters: \(2\), \(1\), \(1.5\).
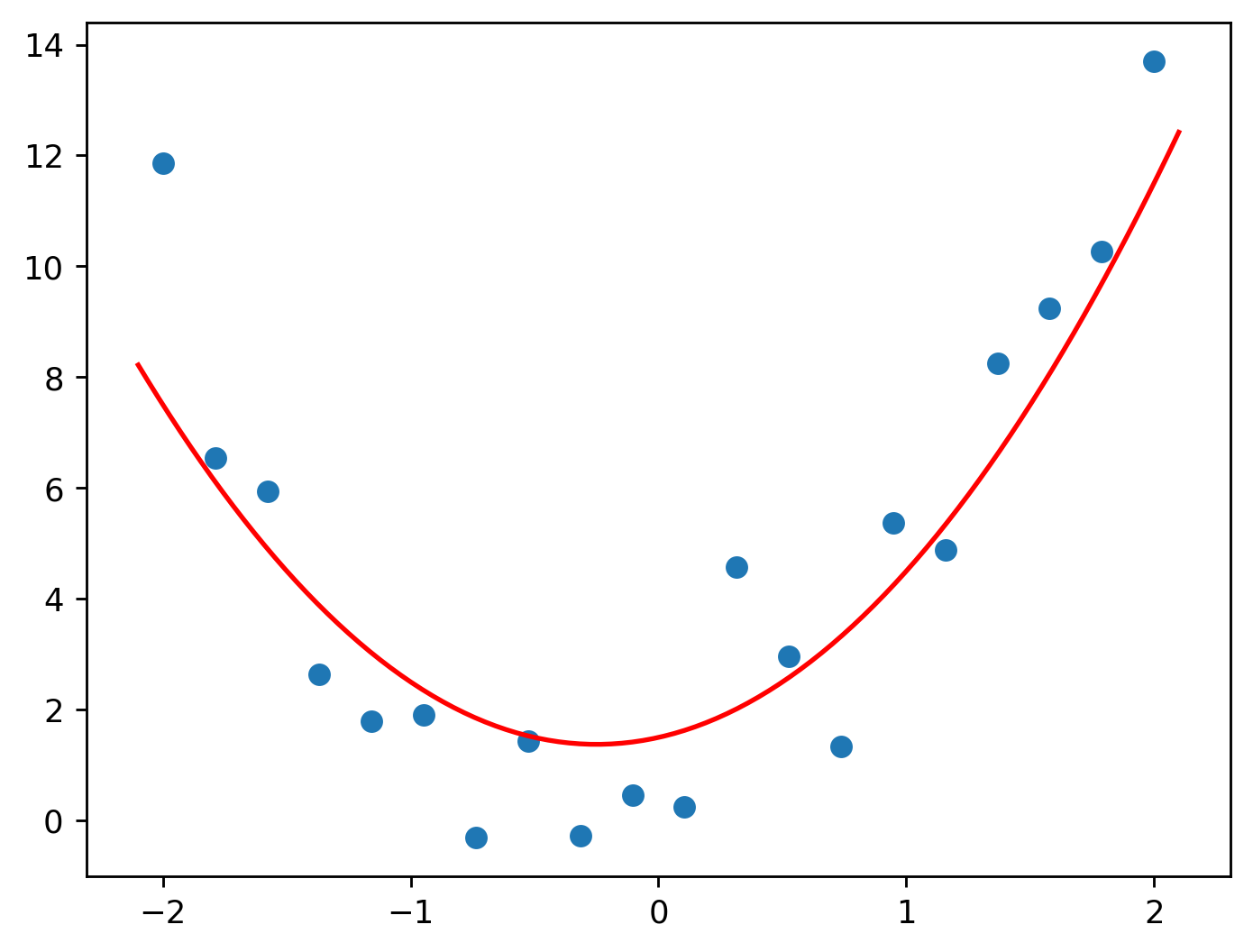
Looking much better now!
Let’s see what \(2\), \(0\), and \(1.5\) gives us.
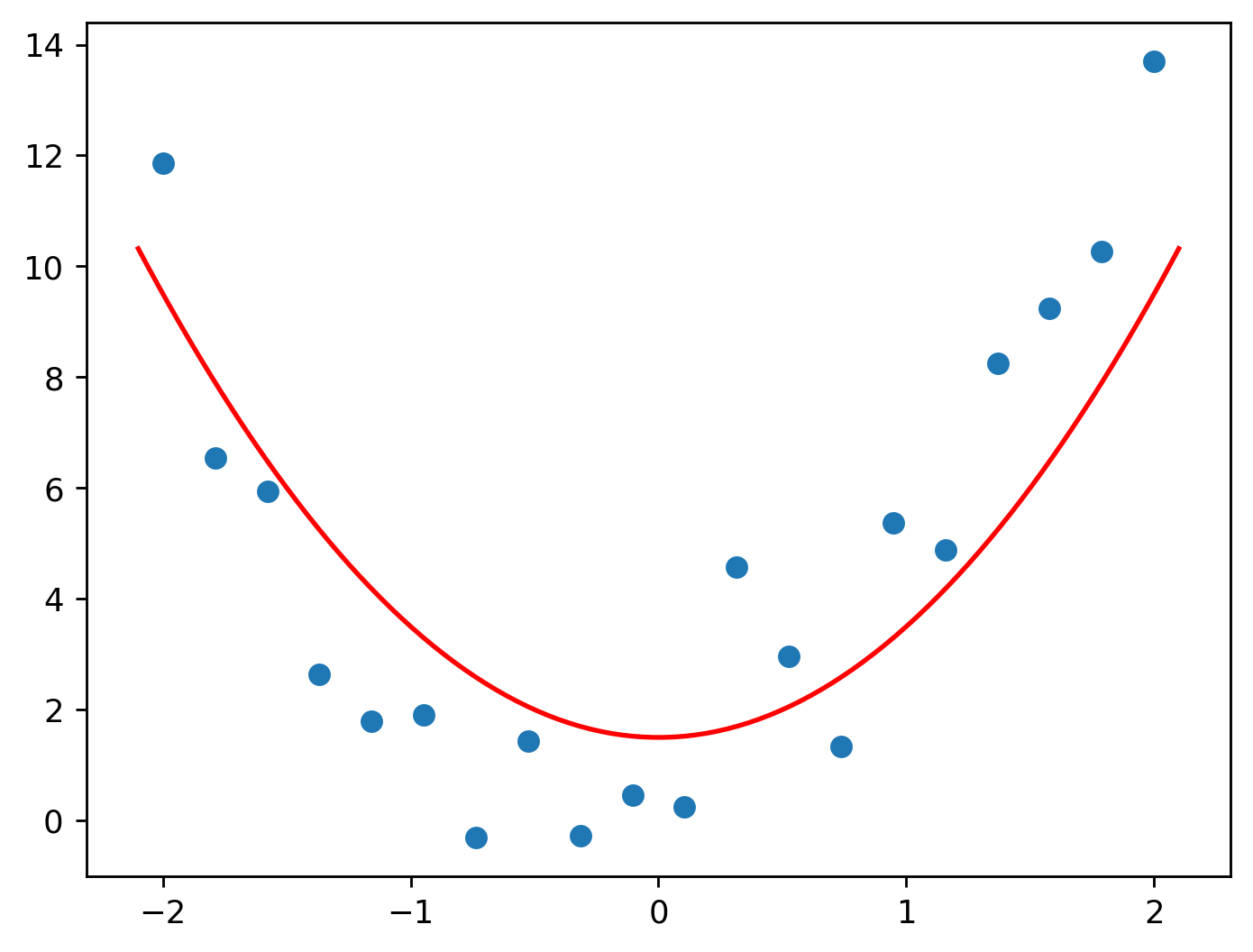
Eyeballing this is difficult. A certain set of parameters we use may be good by looking at the resulting graph, but in reality, it may not be.
What we need is something that can tell us how good our function is; something that tells us whether the changes we are making are actually good or not. To do this, we can calculate a number called the loss. The smaller the loss, the better the function is.
There are many different ways loss can be calculated. The way we will be doing it is known as mean absolute error (MAE). In simple terms, it tells us how far off each prediction is from the actual value. For example, if we have a MAE of 1, this means that, on average, each prediction we make is 1 unit off from the real value.
In our case, a MAE of 1 would mean that each prediction is on average 1 m/s off from the real value.
Let’s repeat what we did above, but this time, we’ll also see what the MAE is.
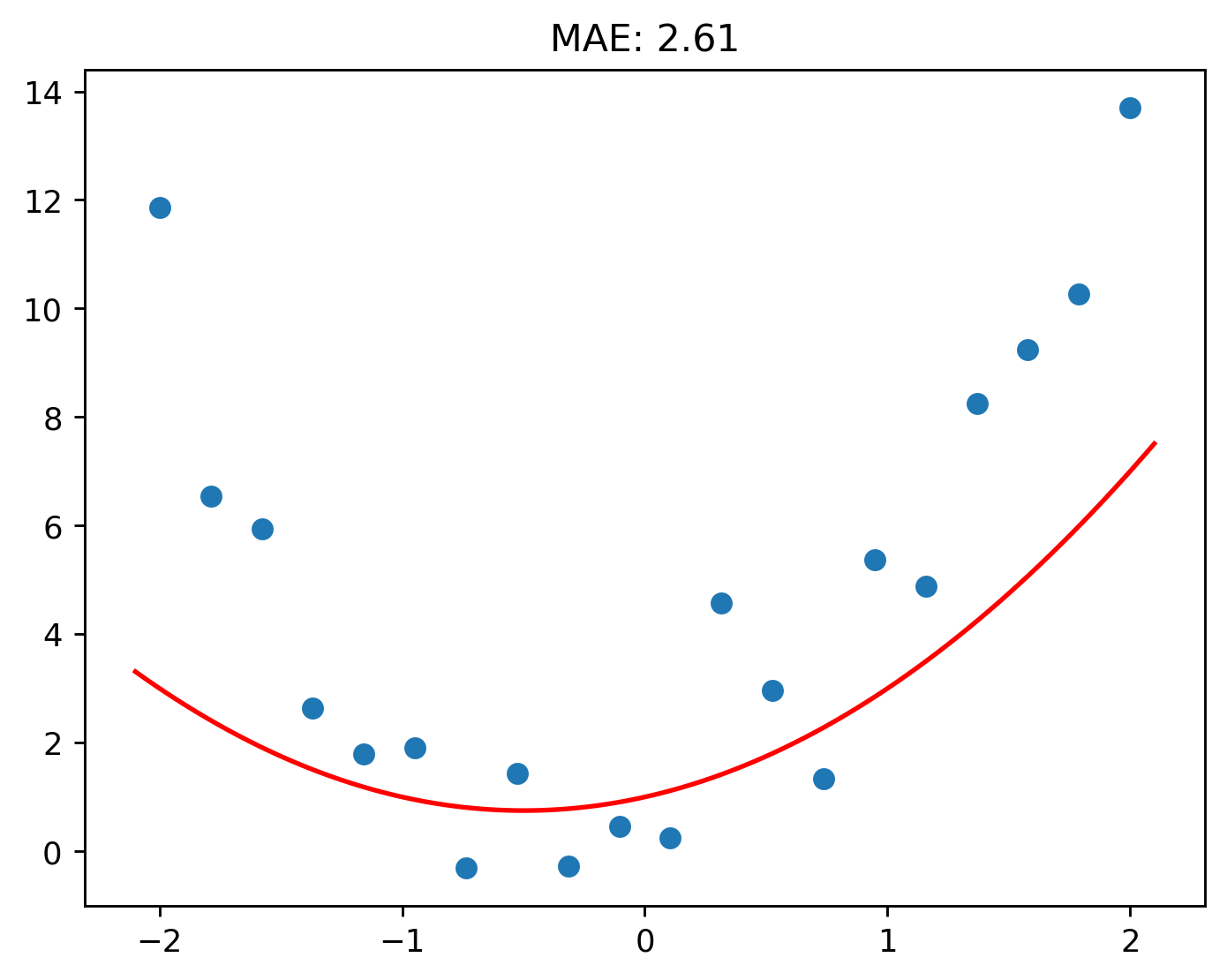
Again, this means that on average, each prediction we will make is 2.61 m/s off from the real value.
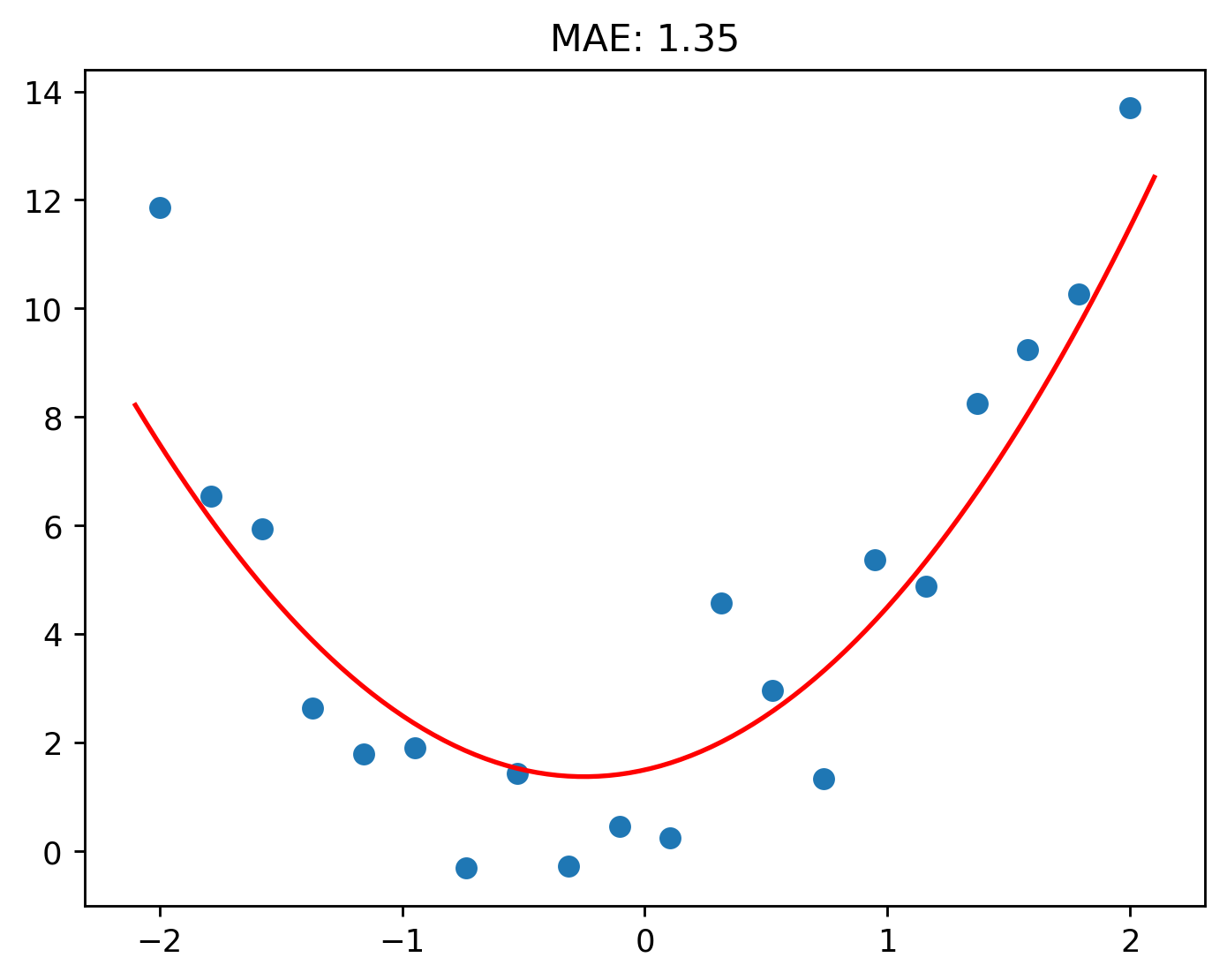
That’s a big jump!
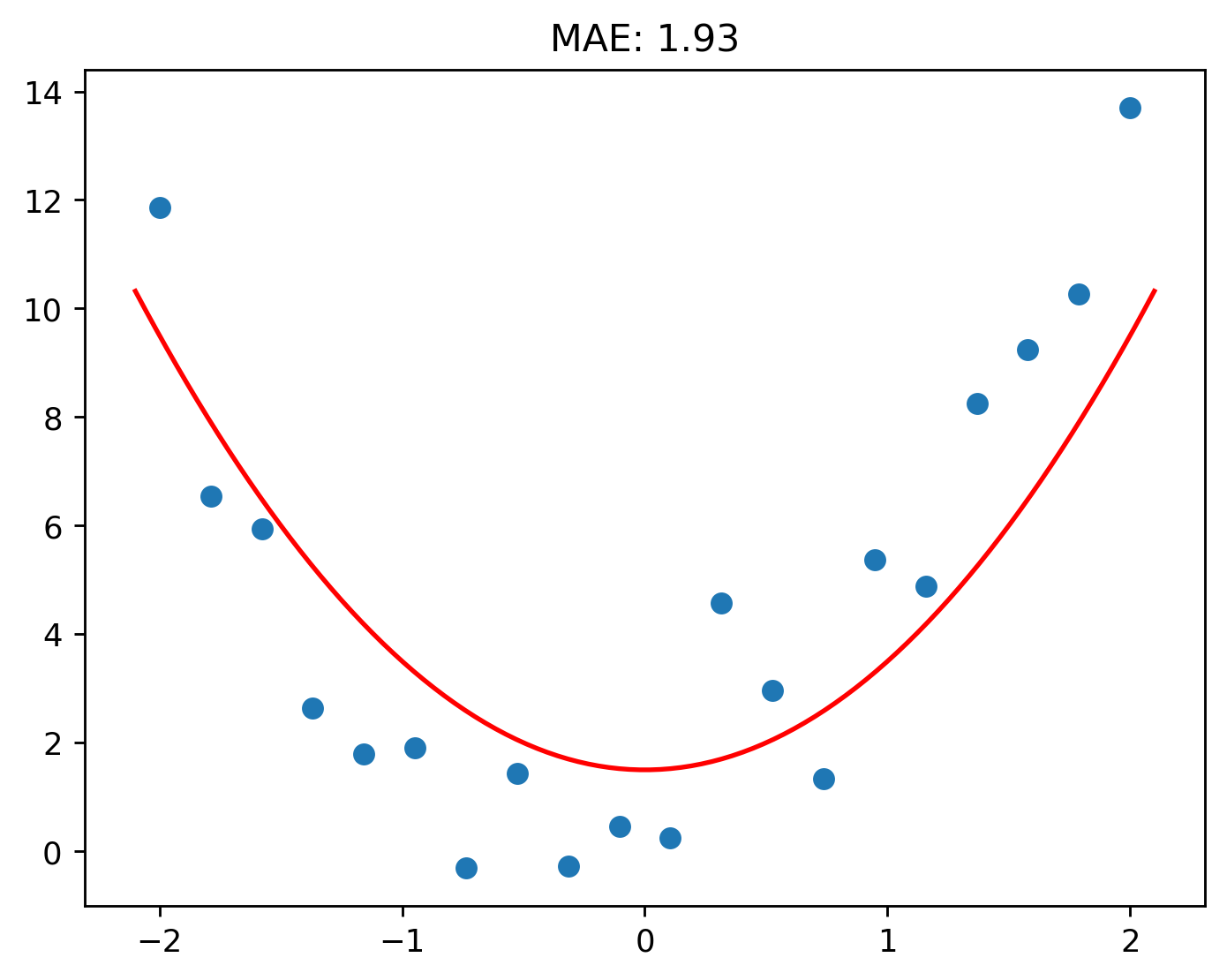
Hmm, things got worse.
Doing this process by hand is very tedious. How do we know if the new set of parameters we are using would improve the function? There needs to be a way to automate this so we don’t have to sit down and do this by hand.
What we can do is update the parameters based on the loss. This would in turn create new parameters that would decrease the loss.
flowchart TB
A[Loss] -- Updates ---> B[Parameters] -- Updates ---> A
Let’s give \(a\), \(b\), and \(c\) an arbitrary set of parameters \(1.1\), \(1.1\), and \(1.1\).
Now let’s create a quadratic with this set of parameters and calculate its mean absolute error.
Now comes the next step: how do we update the parameters based on this loss we have calculated?
To do this, we calculate a new set of quantities known as the gradients. Each parameter has its own gradient.
Let’s say \(a\) has the value of \(1\). If \(a\) has a gradient of value \(0.5\), this would mean that if we increase \(a\) by \(1\), the loss would increase by \(0.5\). Therefore, if we decrease \(a\) by \(1\), this would mean the loss would decrease by \(0.5\), which is what we want!
Read over this once more and it’ll make sense!
Let’s quickly go over the inverse: if \(a\) has a gradient of value \(-0.5\), increasing \(a\) by \(1\) would decrease the loss by \(0.5\) — again, this is what we want! Similarly, decreasing \(a\) by \(1\) would increase the loss by \(0.5\).
The gradients are calculated from the loss. Then the gradients, the current parameters, and along with another value, the parameters are updated to new values. The “another value” is known as the learning rate. The learning rate controls how much the gradients update the parameters.
flowchart TB
A[Gradients]
B[Current Parameters]
C[Learning Rate]
D[Magical Box]
E[Updated Paramters]
A & B & C ---> D ---> E
Lets see this tangibly.
Okay, let’s break this down. The gradient for the first parameter \(a\) is \(-1.35\). This tells us that if we increase the parameter \(a\) by \(1\), our loss will decrease by \(-1.35\). Similary, if we increase the parameter \(b\) by \(1\), this will result in the loss being decreased by \(-0.03\). The same logic holds for \(c\).
Let’s now update the parameters. Remember, the current set of parameters, their gradients, and the learning rate all update the current set of parameters to new values.
We can now repeat the process as many times as desired. Let’s do it 4 times.
Pass: 0; Loss: 2.4010409560416095
Pass: 1; Loss: 1.9847692009423128
Pass: 2; Loss: 1.498316818239171
Pass: 3; Loss: 1.171195547258246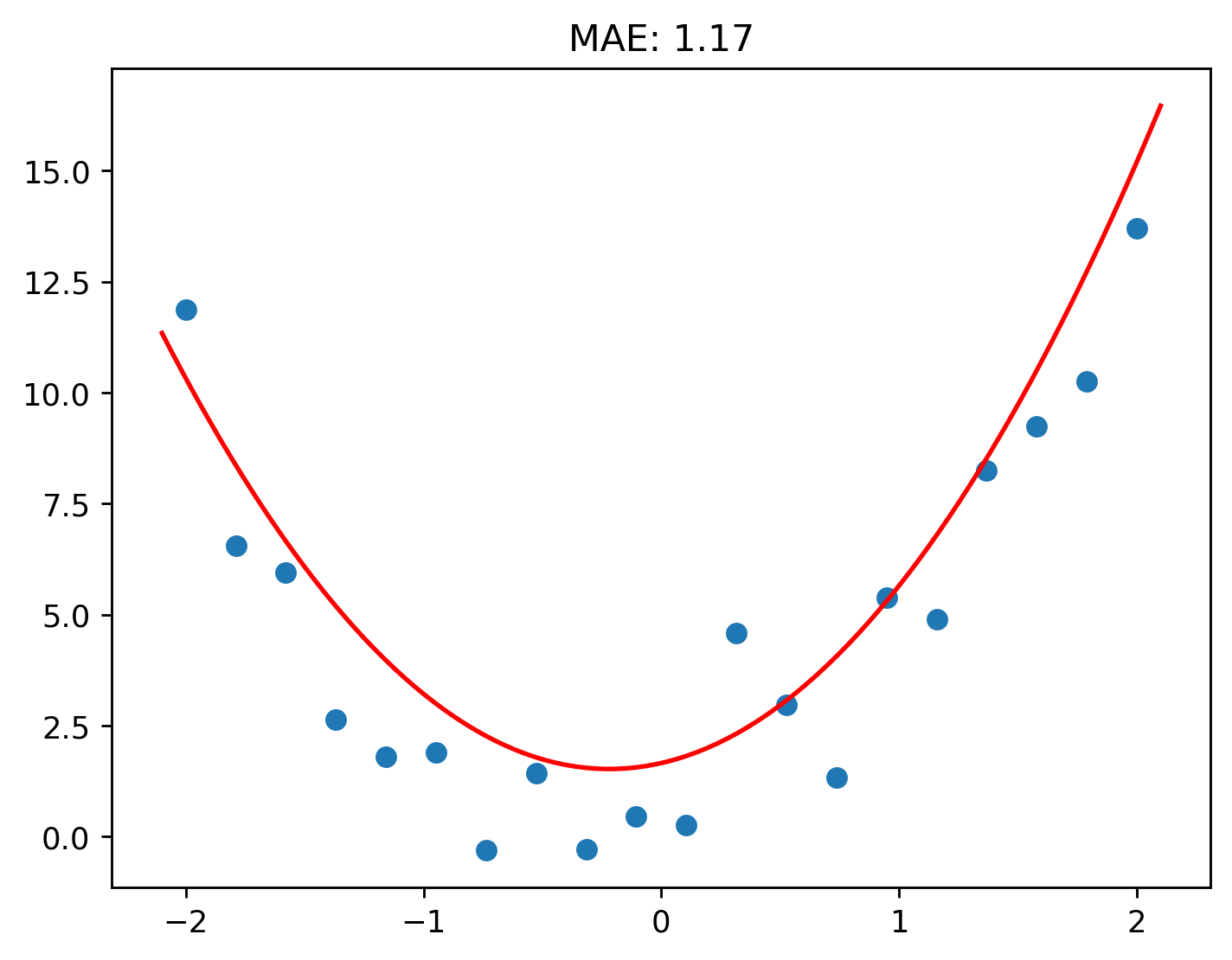
And there you go! An even better fitting quadratic!
Let’s see what the object’s speed is at 1 second.
That roughly seems right!
Let’s see what the object’s speed would be at 3 seconds.
And now, the diagram below should make sense!
flowchart TB
B[Calculate Loss] --> C[Calculate Gradients] --> D[Update Parameters] --> B
The Cool Case: ReLUs
The quadratic example above is a nice, simple way to get a grasp of things. However, you may be wondering, “What if the data doesn’t follow a quadratic shape? What do we do then?”
And that’s a good question! What if our data doesn’t follow any sort of mathematical shape? What if we don’t even know the shape the data will follow? How do we know what function to use in that case?
There is a solution to that! There is an easy way to create a function that bends and twists itself to fit the data; an “unbound” function of sorts, as I like to call it.
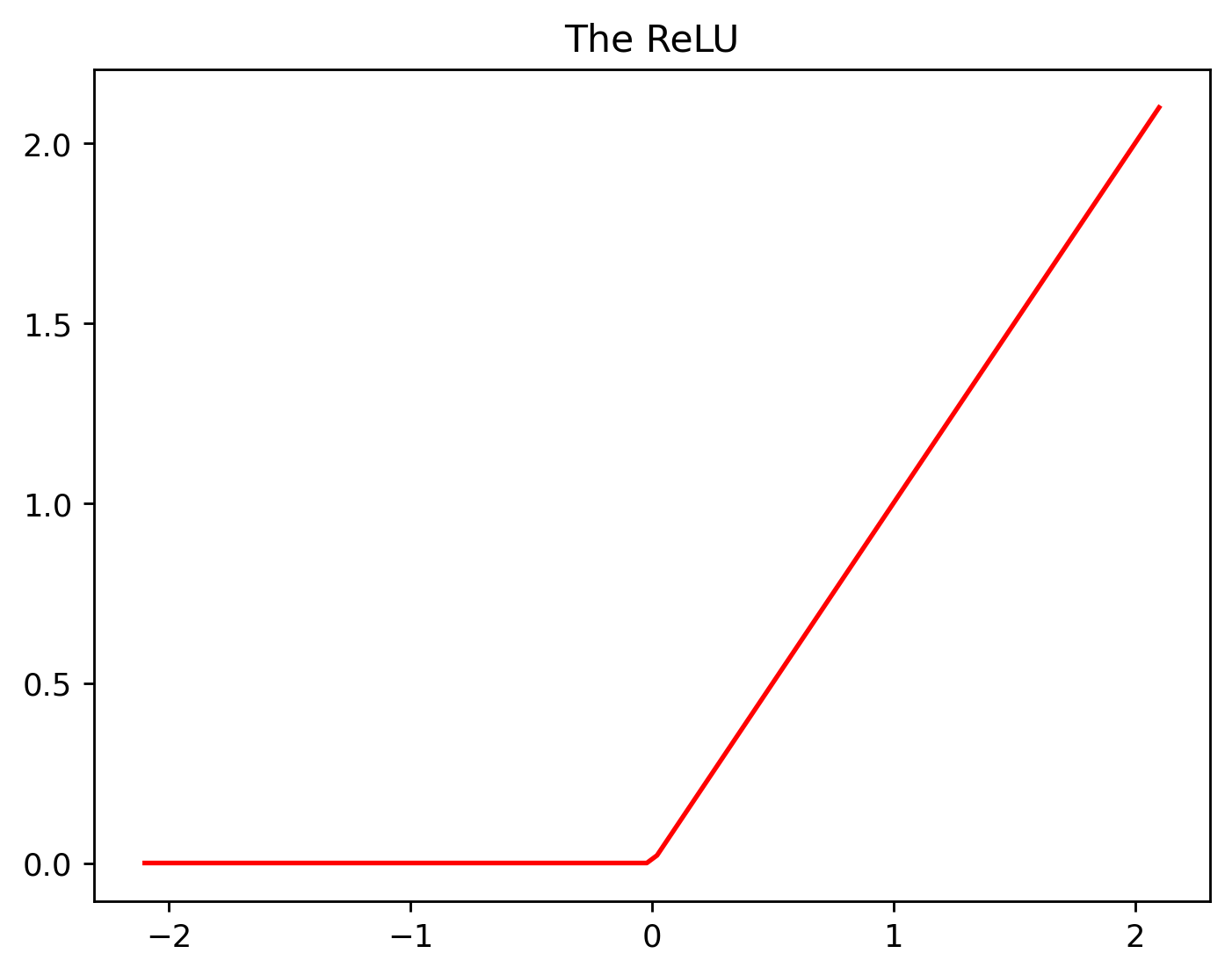
This can be achieved by using another equation known as the ReLU. Another fancy word that can make you sound like a professional, while also being really simple. ReLU is short for Rectified Linear Unit.
The ReLU takes any value that is less than 0, and converts to 0.
Let’s see this.
Take the following line. It has both positive and negative values on the vertical axis.
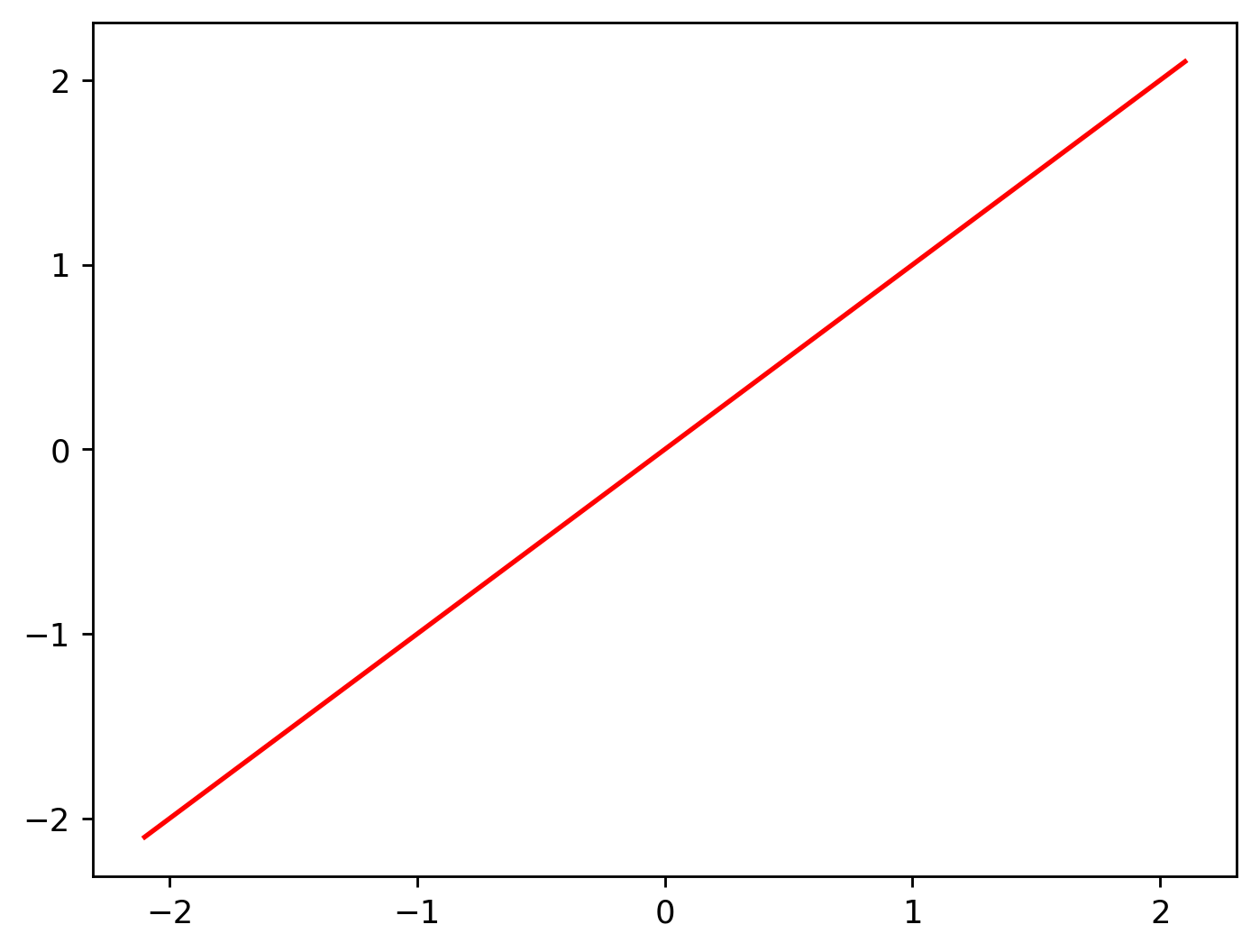
When we use a ReLU, all negative values are converted to zero.
Let’s return to our original data.
Now a single ReLU won’t work as seen below.
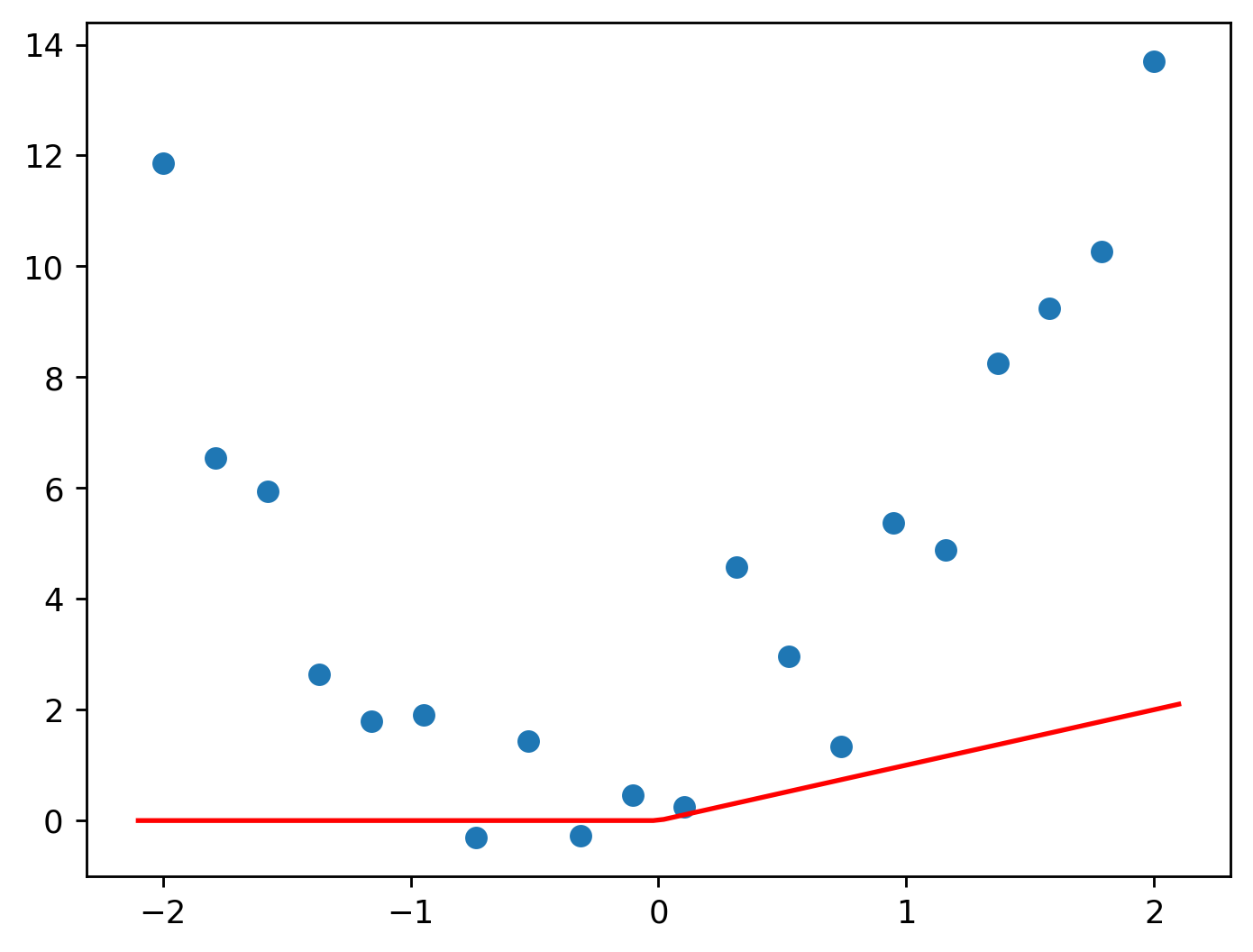
Even after we try to fit it.
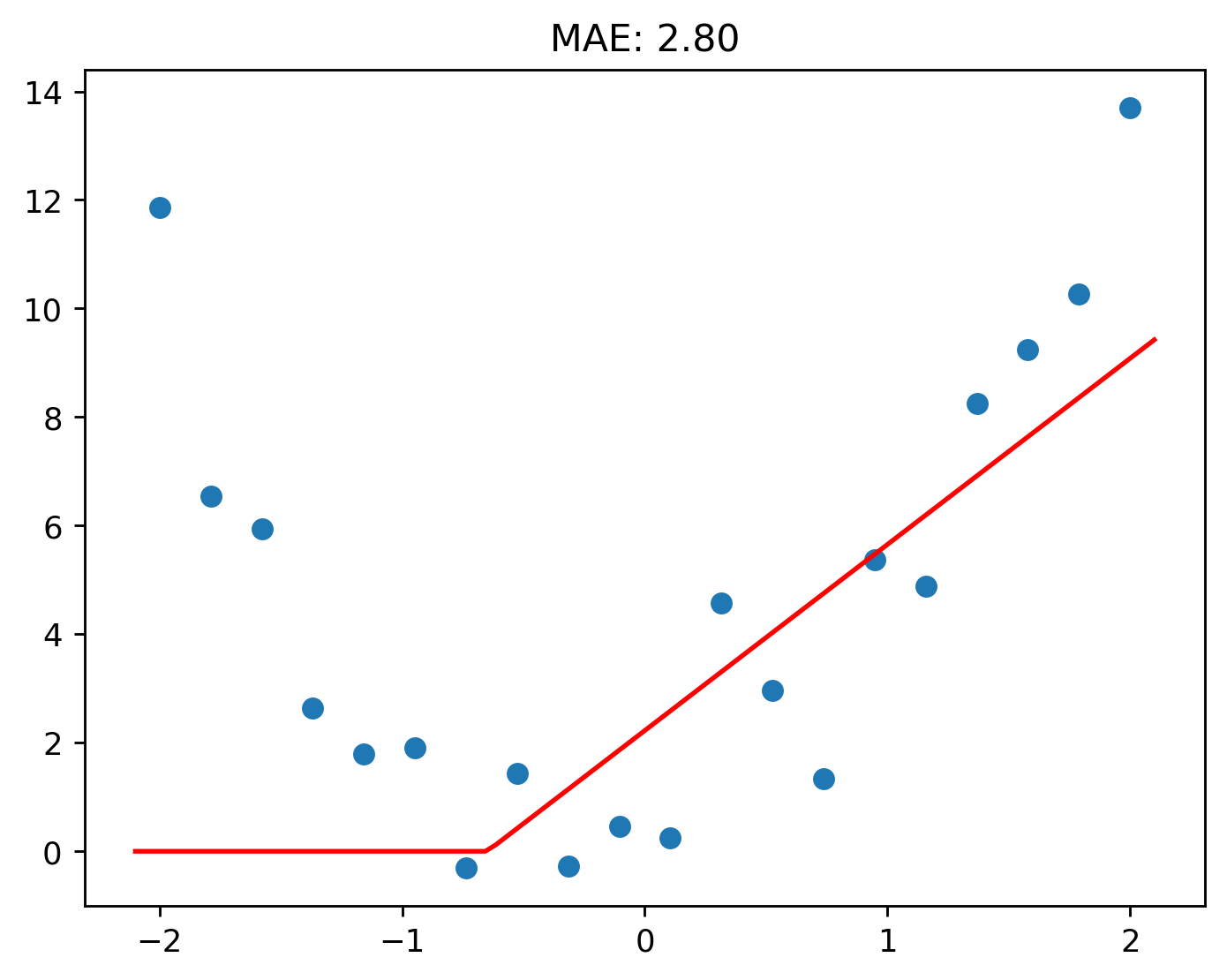
But look at what happens when two ReLUs are, literally, added together!
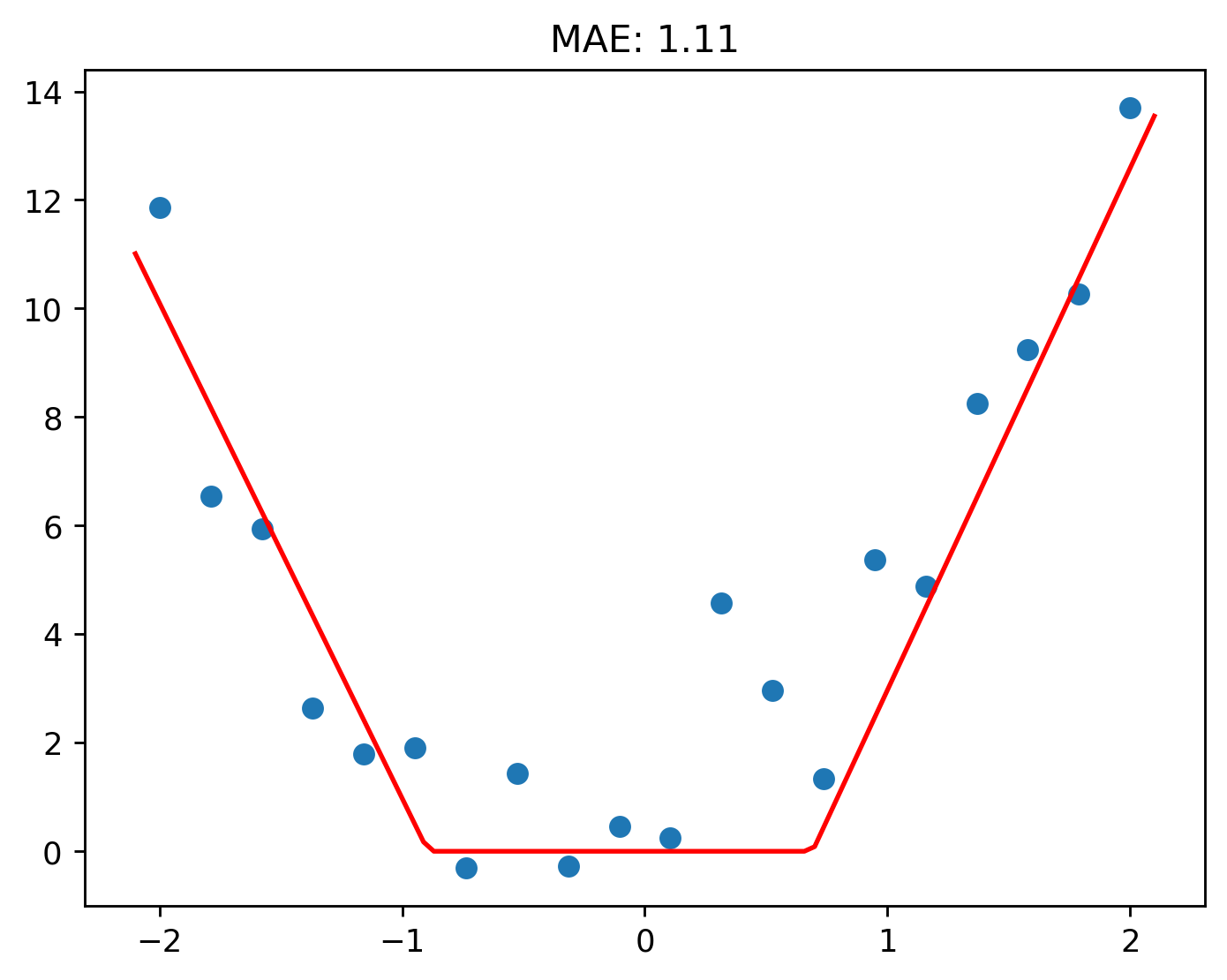
Pretty neat, hey?
Let’s add a third ReLU to the mix.
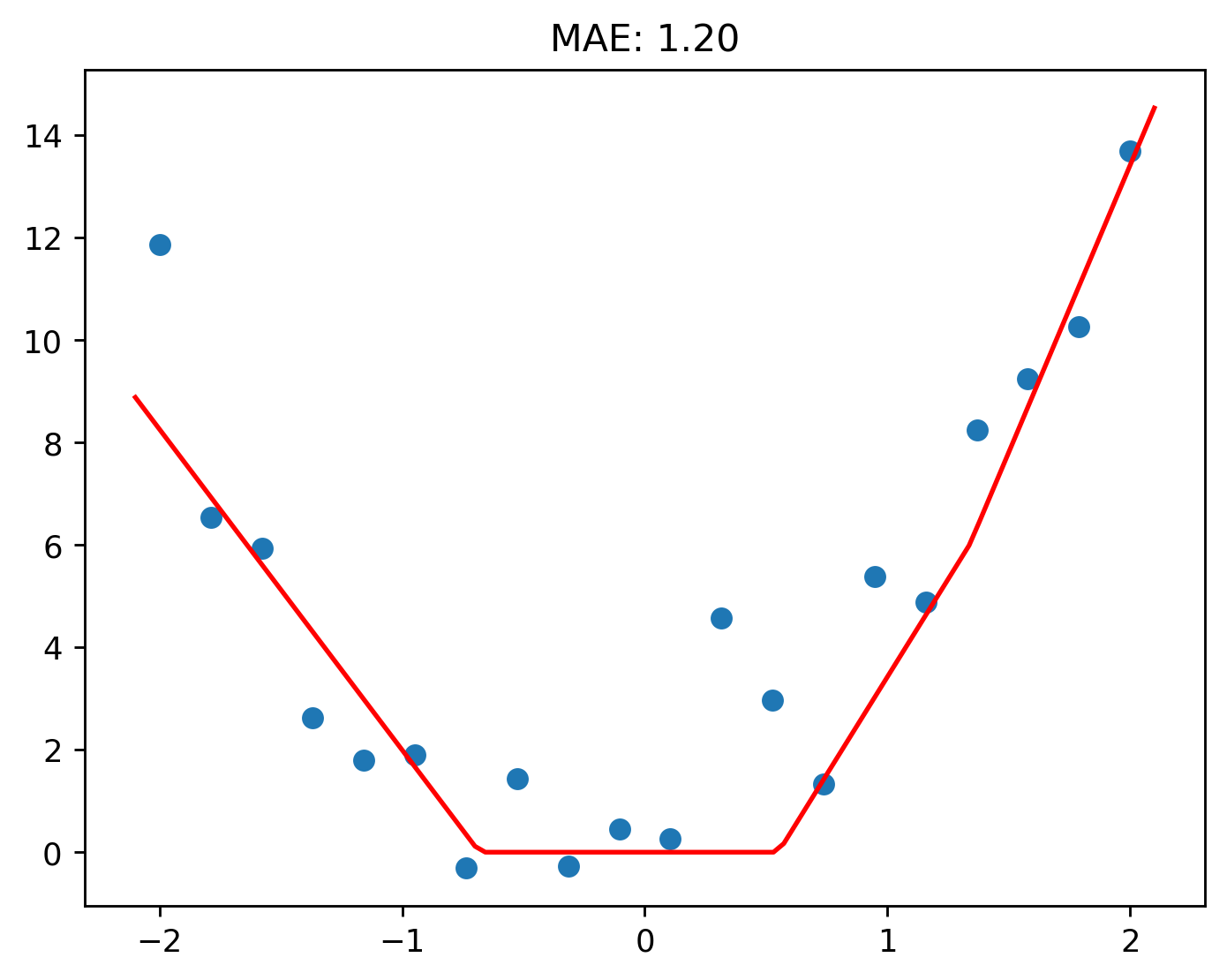
You can see here how the function is adapting to the shape of the data.
With some extra experimentation, I was able to get the loss down to 1.08!
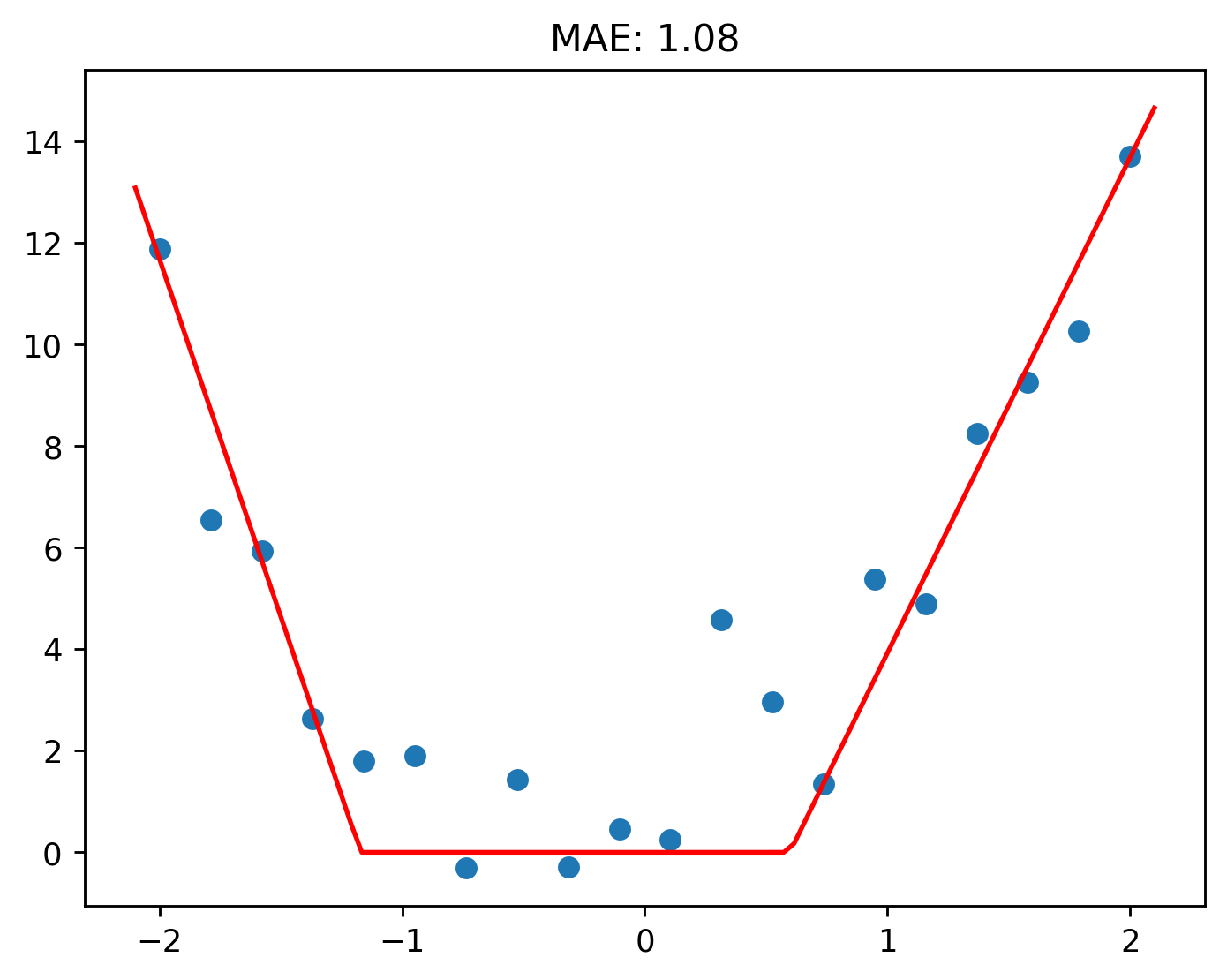
That said, it’s not too much of a difference when compared to two ReLUs.
What if we add 5 more to the mix, for a total of 8?
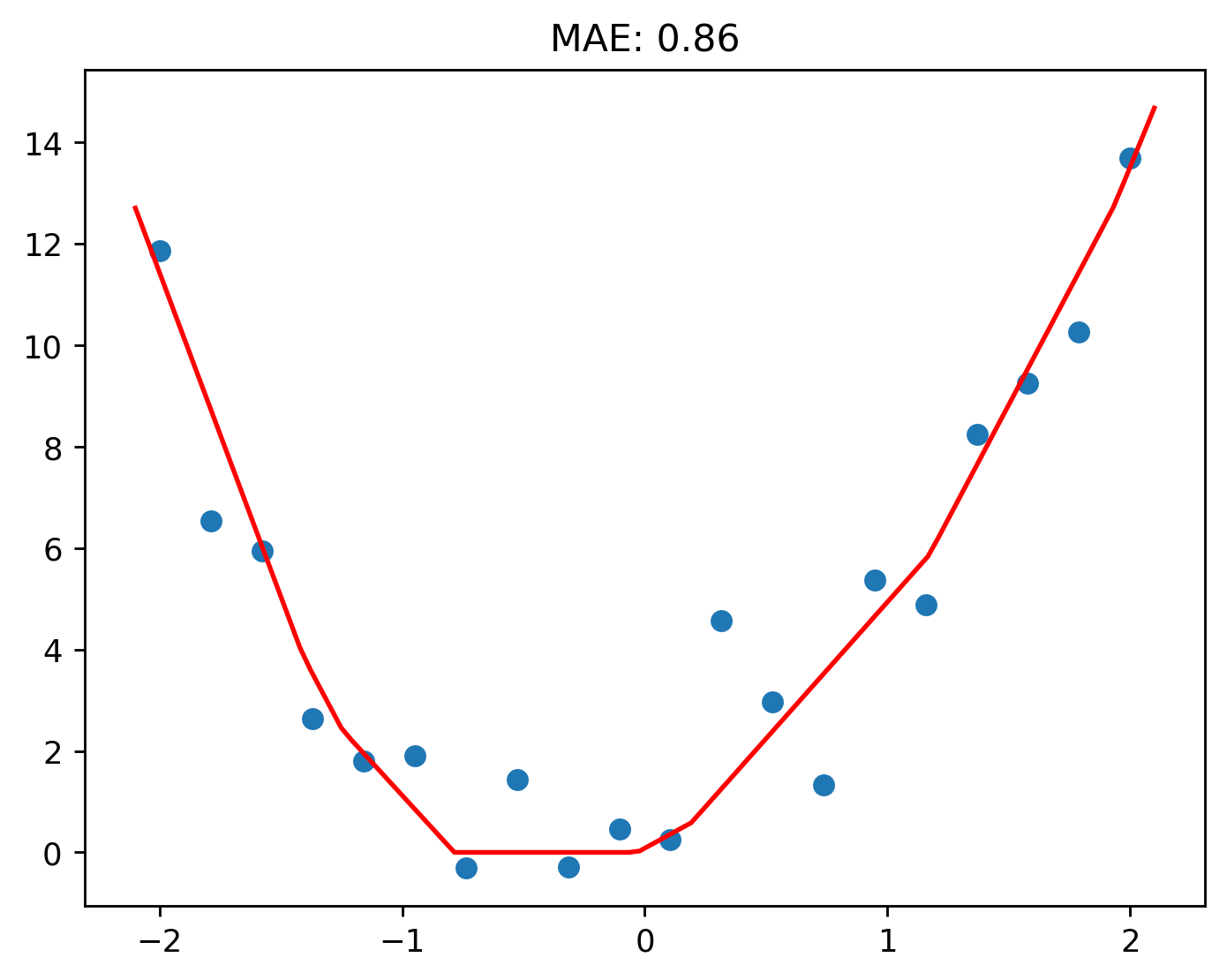
Nice! The MAE has gone below 1!
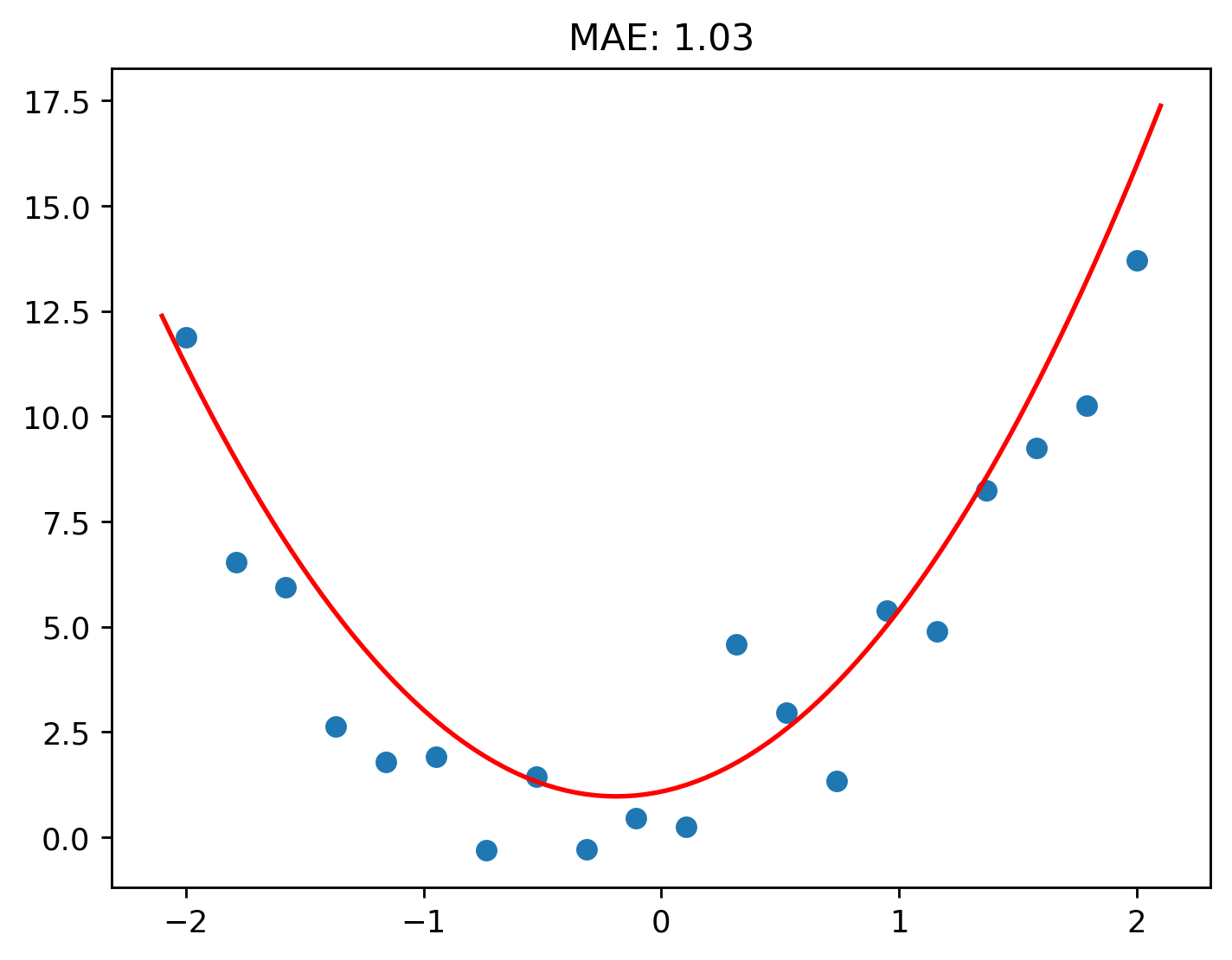
It’s even beat the quadratic function from before! With some expermimenting, I had managed to get the quadratic’s loss down to 1.03.
Let’s use the model that has 8 ReLUs to predict what the object’s velocity would be at 1 second.
Hmm, yes, that is a bit off. But that is fine because overall, the function is a lot more accurate for all the datapoints.
Conclusion
See how easy this stuff all is? All those fancy terms makes this feel complex when in reality, it’s all really simple.
Why not now go and venture off to learn more and implement your own models!
Below are two free courses I can recommend:
-
A great primer into AI. The course goes over the history, the implementations, and the implications of this field, all without needing the knowledge of programming or complex mathematics.
Practical Deep Learning for Coders
This course is different from other AI courses you’ll find. How? Because instead of starting off with the nitty gritty basics, you begin by actually implementing your own simple image classifier (a model that can tell what thing is in an image). You’ll be surprised at how simple it is to implement models with minimal code, and how little you need to know to get started (hint: you only really need high-school maths).
If you have any questions, comments, suggestions, or feedback, please do post them down in the comment section below!