from fastai.vision.all import *Detecting Floods for Disaster Relief
How good are you at detecting floods?
Creating Models
fastai
A rundown of the creation of my flood classifier.
You can find this notebook on Kaggle here.
This article was updated on Friday, 11 November 2022.

The model that will be created in this notebook can detect whether an area shown in an image is flooded or not. The idea for creating this model has been spurred from the recent floodings in Pakistan.
Such models can prove useful in flood relief, helping to detect which areas need immediate focus.
The dataset used to train this model is Louisiana flood 2016, uploaded by Kaggle user Rahul T P, which you can view here.
The fastai library, a high level PyTorch library, has been used.
One of the points of this notebook is to showcase how simple it is to create powerful models. That said, this notebook is not a tutorial or guide.
Sort data.
The data in the dataset needs to be organized into train and valid folders. Each will contain the same subfolders, 0 and 1, which will be used to label the data. A label of 0 indicates the area shown in the image is not flooded, while a label of 1 indicates the area shown in the image is flooded.
The images in the dataset itself has been organized as follows:
If no underscore is in the file name, the image shows the area before or after the flood.
If an underscore is in the file name, the image shows the area during the flood:
- If a zero follows the underscore, the area was not flooded.
- If a one follows the underscore, the area was flooded.
Creating the necessary paths.
working_path = Path.cwd(); print(working_path)
folders = ('train', 'valid')
labels = ('0', '1')/kaggle/workinginput_path = Path('/kaggle/input')
train_image_paths = sorted(input_path.rglob('train/*.png'))
valid_image_paths = sorted(input_path.rglob('test/*.png'))
len(train_image_paths), len(valid_image_paths)(270, 52)Creating the necessary directories.
for folder in folders:
if not (working_path/folder).exists():
(working_path/folder).mkdir()
for label in labels:
if not (working_path/folder/label).exists():
(working_path/folder/label).mkdir()Move images to new directories.
try:
for image_path in train_image_paths:
if '_1' in image_path.stem:
with (working_path/'train'/'1'/image_path.name).open(mode='xb') as f:
f.write(image_path.read_bytes())
else:
with (working_path/'train'/'0'/image_path.name).open(mode='xb') as f:
f.write(image_path.read_bytes())
except FileExistsError:
print("Training images have already been moved.")
else:
print("Training images moved.")Training images moved.try:
for image_path in valid_image_paths:
if '_1' in image_path.stem:
with (working_path/'valid'/'1'/image_path.name).open(mode='xb') as f:
f.write(image_path.read_bytes())
else:
with (working_path/'valid'/'0'/image_path.name).open(mode='xb') as f:
f.write(image_path.read_bytes())
except FileExistsError:
print("Testing images have already been moved.")
else:
print("Testing images moved.")Testing images moved.Check that images have been moved.
training_images = get_image_files(working_path/'train'); print(len(training_images))270Image.open(training_images[0])
validation_images = get_image_files(working_path/'valid'); print(len(validation_images))52Image.open(validation_images[-1])
Load data
Create the training and validation dataloaders through fastai’s quick and easy DataBlock class.
dataloaders = DataBlock(
blocks = (ImageBlock, CategoryBlock),
get_items = get_image_files,
splitter = GrandparentSplitter(),
get_y = parent_label,
item_tfms = [Resize(192, method='squish')]
).dataloaders(working_path, bs=32)Check that data has been loaded correctly.
dataloaders.show_batch(max_n=8)
Instantiate and Train Model
learner = vision_learner(dataloaders, resnet18, metrics=error_rate)
learner.fine_tune(9)Downloading: "https://download.pytorch.org/models/resnet18-f37072fd.pth" to /root/.cache/torch/hub/checkpoints/resnet18-f37072fd.pth| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.919323 | 1.118264 | 0.365385 | 00:09 |
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.490039 | 0.628054 | 0.250000 | 00:02 |
| 1 | 0.367996 | 0.411558 | 0.192308 | 00:02 |
| 2 | 0.266664 | 0.472146 | 0.192308 | 00:02 |
| 3 | 0.203069 | 0.256436 | 0.115385 | 00:03 |
| 4 | 0.158453 | 0.127106 | 0.076923 | 00:03 |
| 5 | 0.124499 | 0.095927 | 0.038462 | 00:02 |
| 6 | 0.098409 | 0.089279 | 0.038462 | 00:03 |
| 7 | 0.079600 | 0.093277 | 0.038462 | 00:02 |
| 8 | 0.064886 | 0.090372 | 0.038462 | 00:02 |
Nice! A relatively low error rate for no tweaking.
Visualizing Mistakes
We have to see how the model is getting confuzzled.
interp = ClassificationInterpretation.from_learner(learner)
interp.plot_confusion_matrix()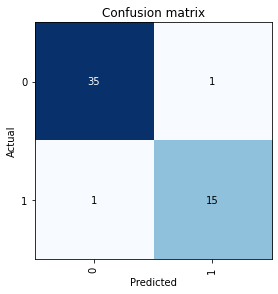
Only a couple of mistakes. Let’s see what they are.
interp.plot_top_losses(5, nrows=1)
Nothing has been mislabeled, but the first one is especially tricky to determine, even for human eyes.
Model Inference
Let’s test the model on some images of the recent flooding in Pakistan.
def infer_image(image_path):
display(Image.open(image_path))
label, _, probabilities = learner.predict(PILImage(PILImage.create(image_path)))
if label == '0':
print(f"The area shown in the image is not flooded with probability {probabilities[0]*100:.2f}%.")
elif label == '1':
print(f"The area shown in the image is flooded with probability {probabilities[1]*100:.2f}%.")
else:
print("Unknown label assigned to image.")infer_image(input_path/'floodclassifiertestset'/'1'/'1.jpeg')
The area shown in the image is not flooded with probability 65.65%.Not bad!
Let’s try it on another image.
infer_image(input_path/'floodclassifiertestset'/'1'/'2.jpg')
The area shown in the image is flooded with probability 99.90%.The label for this image is kind of meaningless. This is an image of a vast area of land, so certain areas could be flooded, while others are not. That said, it could be used to determine whether there is flooding in the image.
infer_image(input_path/'floodclassifiertestset'/'1'/'3.jpg')
The area shown in the image is flooded with probability 99.99%.The model performed really well in this case: the input image is shown at a different angle. The images in the training set only show areas from a top-down view.
infer_image(input_path/'floodclassifiertestset'/'1'/'4.jpg')
The area shown in the image is not flooded with probability 64.56%.Over here, the limitations of the current state of the model can be seen. The model is not performing well on images where the view is more parallel to the ground, since the images in the training set are all top-down.
Let’s do two more images.
infer_image(input_path/'floodclassifiertestset'/'1'/'5.jpg')
The area shown in the image is flooded with probability 99.94%.infer_image(input_path/'floodclassifiertestset'/'1'/'6.jpg')
The area shown in the image is flooded with probability 100.00%.The model is working well with images of different sizes too, and has given this image a very high, correct confidence.
Improving the model.
Let’s see if we can get the model’s performance to improve on the following image through augmenting the training set.
Image.open(input_path/'floodclassifiertestset'/'1'/'4.jpg')
augmented_dataloaders = DataBlock(
blocks = (ImageBlock, CategoryBlock),
get_items = get_image_files,
splitter = GrandparentSplitter(),
get_y = parent_label,
item_tfms = RandomResizedCrop(192, min_scale=0.5),
batch_tfms=aug_transforms()
).dataloaders(working_path, bs=32)augmented_dataloaders.show_batch(max_n=8)
augmented_learner = vision_learner(augmented_dataloaders, resnet18, metrics=error_rate)
augmented_learner.fine_tune(9)| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 1.161182 | 0.835870 | 0.365385 | 00:02 |
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.442552 | 0.686252 | 0.288462 | 00:03 |
| 1 | 0.417739 | 0.411907 | 0.153846 | 00:02 |
| 2 | 0.346400 | 0.316388 | 0.057692 | 00:03 |
| 3 | 0.306782 | 0.213407 | 0.076923 | 00:02 |
| 4 | 0.251947 | 0.199586 | 0.076923 | 00:02 |
| 5 | 0.209951 | 0.141818 | 0.057692 | 00:02 |
| 6 | 0.188433 | 0.116713 | 0.057692 | 00:03 |
| 7 | 0.169689 | 0.125078 | 0.057692 | 00:02 |
| 8 | 0.151843 | 0.131188 | 0.057692 | 00:02 |
Let’s try the new model out.
display(Image.open(input_path/'floodclassifiertestset'/'1'/'4.jpg'))
label, _, probabilities = augmented_learner.predict(PILImage(PILImage.create(input_path/'floodclassifiertestset'/'1'/'4.jpg')))
if label == '0':
print(f"The area shown in the image is not flooded with probability {probabilities[0]*100:.2f}%.")
elif label == '1':
print(f"The area shown in the image is flooded with probability {probabilities[1]*100:.2f}%.")
else:
print("Unknown label assigned to image.")
The area shown in the image is flooded with probability 99.91%.Dang, impressive! The correct label and with excellent confidence!
Before we get too excited though, we should check the performance on the model with the previous images.
test_dataloader = learner.dls.test_dl([image_path for image_path in sorted((input_path/'floodclassifiertestset').rglob('*.*'))])probabilities, _, labels = augmented_learner.get_preds(dl=test_dataloader, with_decoded=True)print("Images are numbered horizontally.")
test_dataloader.show_batch()
for probability, label, image_number in zip(probabilities, labels, range(1, 7)):
if label == 1:
print(f"Image {image_number} is flooded with a probability of {probability[1]*100:.2f}%.")
elif label == 0:
print(f"Image {image_number} is not flooded with a probability of {probability[0]*100:.2f}%.")
else:
print(f"Image {image_number} has been assigned an unknown label.")Images are numbered horizontally.
Image 1 is flooded with a probability of 95.94%.
Image 2 is flooded with a probability of 99.92%.
Image 3 is flooded with a probability of 91.34%.
Image 4 is flooded with a probability of 99.71%.
Image 5 is flooded with a probability of 100.00%.
Image 6 is flooded with a probability of 100.00%.
Drastically improved probabilities! A little augmentation can go a long way.
Takeaways
This model was trained on only 270 images and minimal code. Accessbility and abstraction to the field of machine learning has come a long, long way. Given the right data and the right pretrained model, a powerful model can be produced in less than an hour, if not half.
This is important: in disasters such as floods, the time taken to produce the logistics required for relief can be drastically reduced. It is also important because the barrier of entry to this field is dramatically lowered; more people can create powerful models, in turn producing better solutions.
However, there could be some improvements and additions made to the model:
Include a third class to the model. Images that are not flooded, but show signs of having been flooded would be assigned this class. The dataset used for this model includes such images.
Train the model on images that include a variety of geographic locations and dwellings. The current dataset only contains images taken in a lush, green area with plenty of trees; infrastructure looks a certain way; the color of the floodwater is also dependent on the surroundings. All this makes the model good a prediciting whether an image is flooded for images with certain features.
If you have any comments, questions, suggestions, feedback, criticisms, or corrections, please do post them down in the comment section below!