The State of Pose Estimation
What pose is pose estimation in?
Foreword
In this post, I have annotated a presentation I gave at my univesity’s multimodal intelligence lab. I’m a newcomer to general purpose robotics, so I had a different mindset and perspective going in.
At the end of this post, I provide another perspective that arose as I wrote these annotations.
Annotated Presentation
Here, I introduce the task assigned to me, which focused on addressing the limitations of VLMs in understanding object poses through fine-tuning on annotated videos.
The core problem is that current vision-language models (VLMs) struggle with understanding object poses. When queried about an object’s orientation or directional changes, VLMs often fail when even simple complexity is introduced or they forget the object’s prior states.
The goal is to fine-tune a VLM on videos annotated with pose information to improve its performance in understanding and reasoning about object poses.
Two main obstacles exist: data and pose models.
A major obstacle is the lack of existing annotated video datasets with object pose information. Self-recorded samples suffer from limited diversity and aren’t suitable for achieving generalizability. While off-the-shelf video datasets exist, they can’t be easily processed due to pose model requirements.
Pose estimation models present significant friction due to their specialized input requirements (camera data, reference images, 3D models) and fragmented ecosystem. There’s no standardized text-to-pose interface, requiring manual masking and setup of different libraries/environments for each model.
The current workflow involves too much friction and insufficient iteration, leading to a lack of confidence in the self-created dataset approach.
Quick iteration is key. Quick iteration is key. Quick iteration is key.
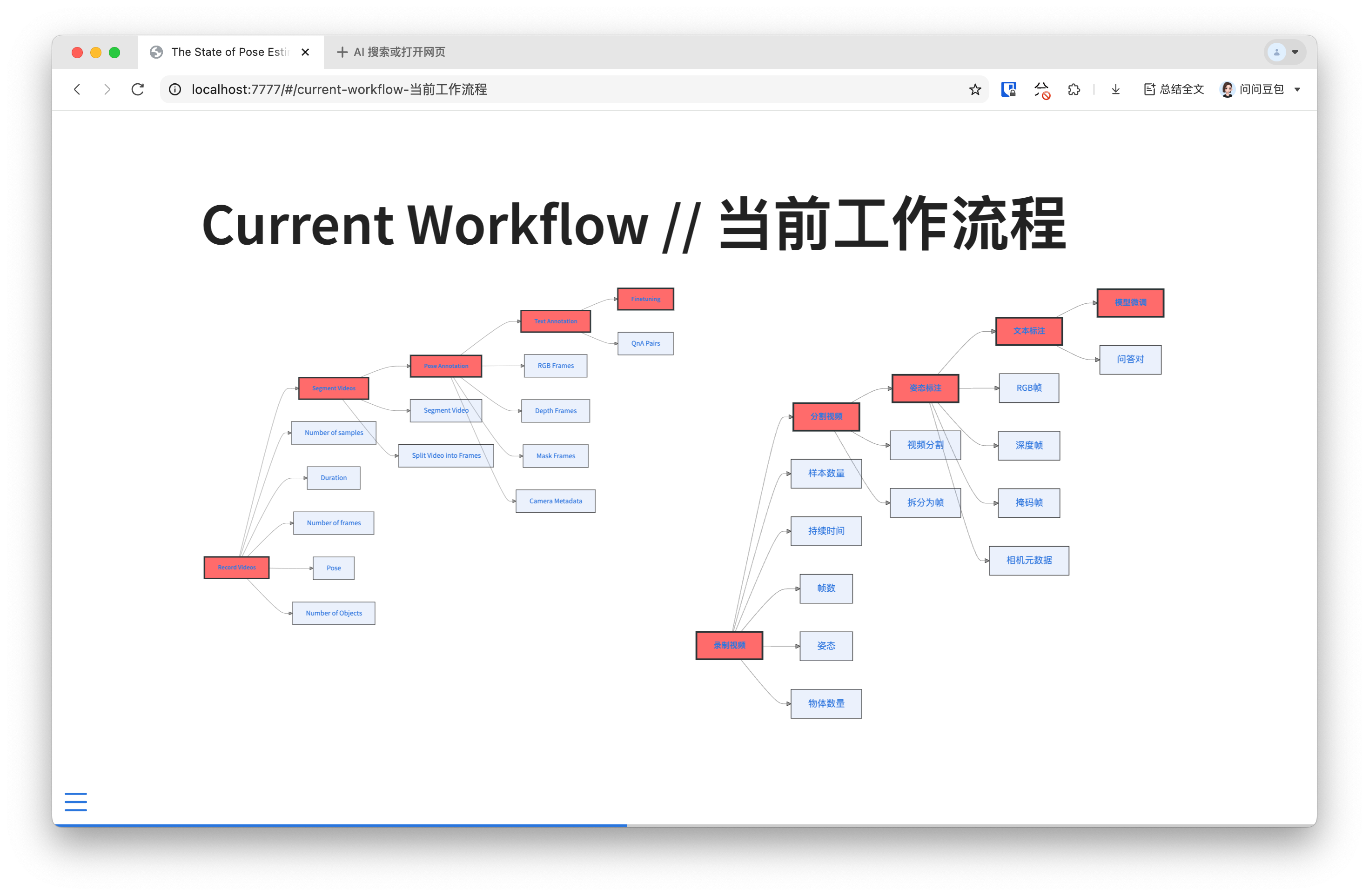
The workflow involves multiple steps with numerous variables: recording videos (sample count, duration, frames, pose complexity, object count), segmenting videos into frames, pose annotation (RGB, depth, mask frames, camera metadata), text annotation (QnA pairs), and finally fine-tuning. Each step introduces significant time investment and uncertainty.
The creation of this dataset is a whole project of its own, with the pose model itself being the core component.
So I suggested a different direction: why not test the underlying theory but with those pieces of data that have less friction.
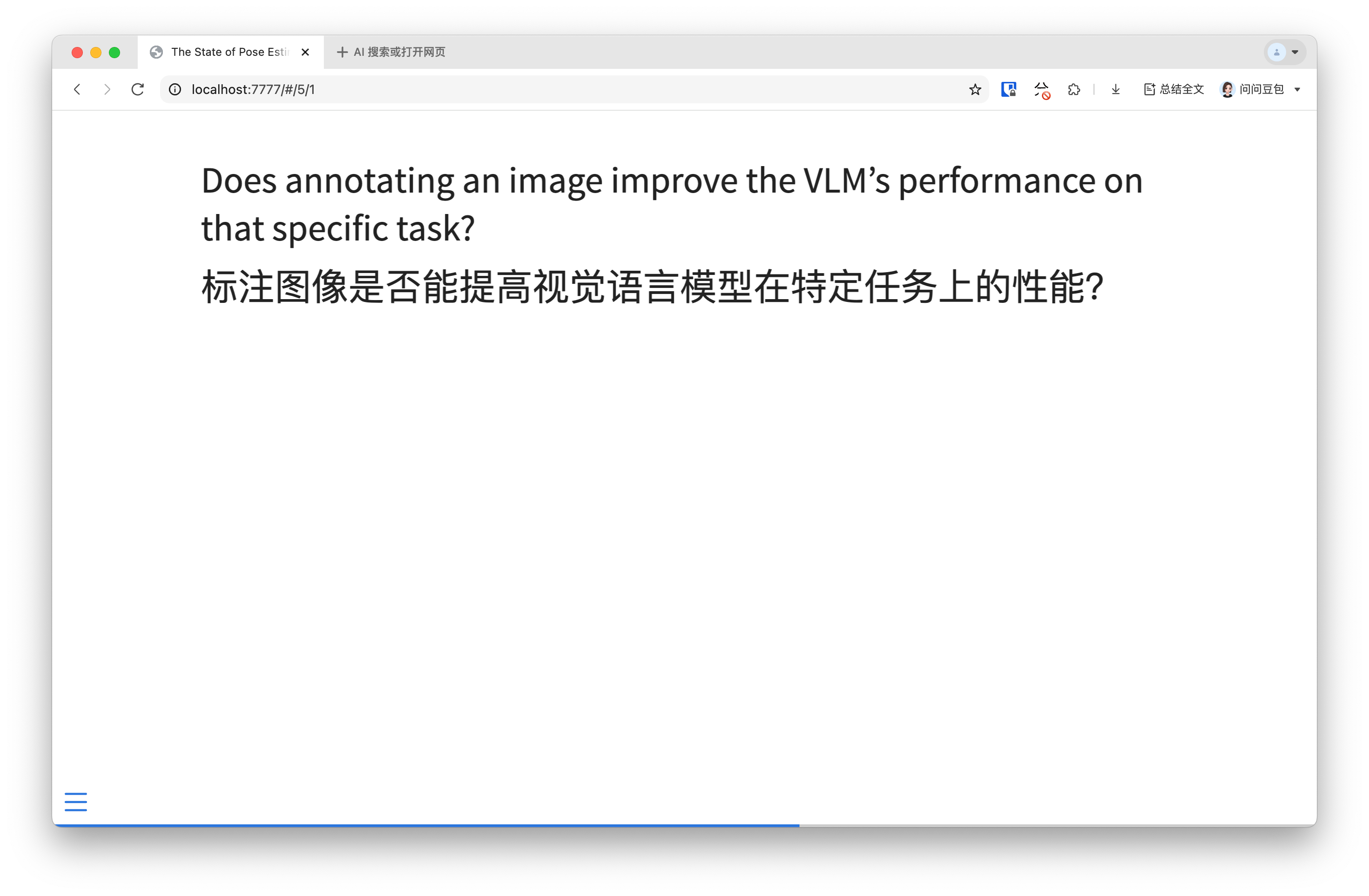
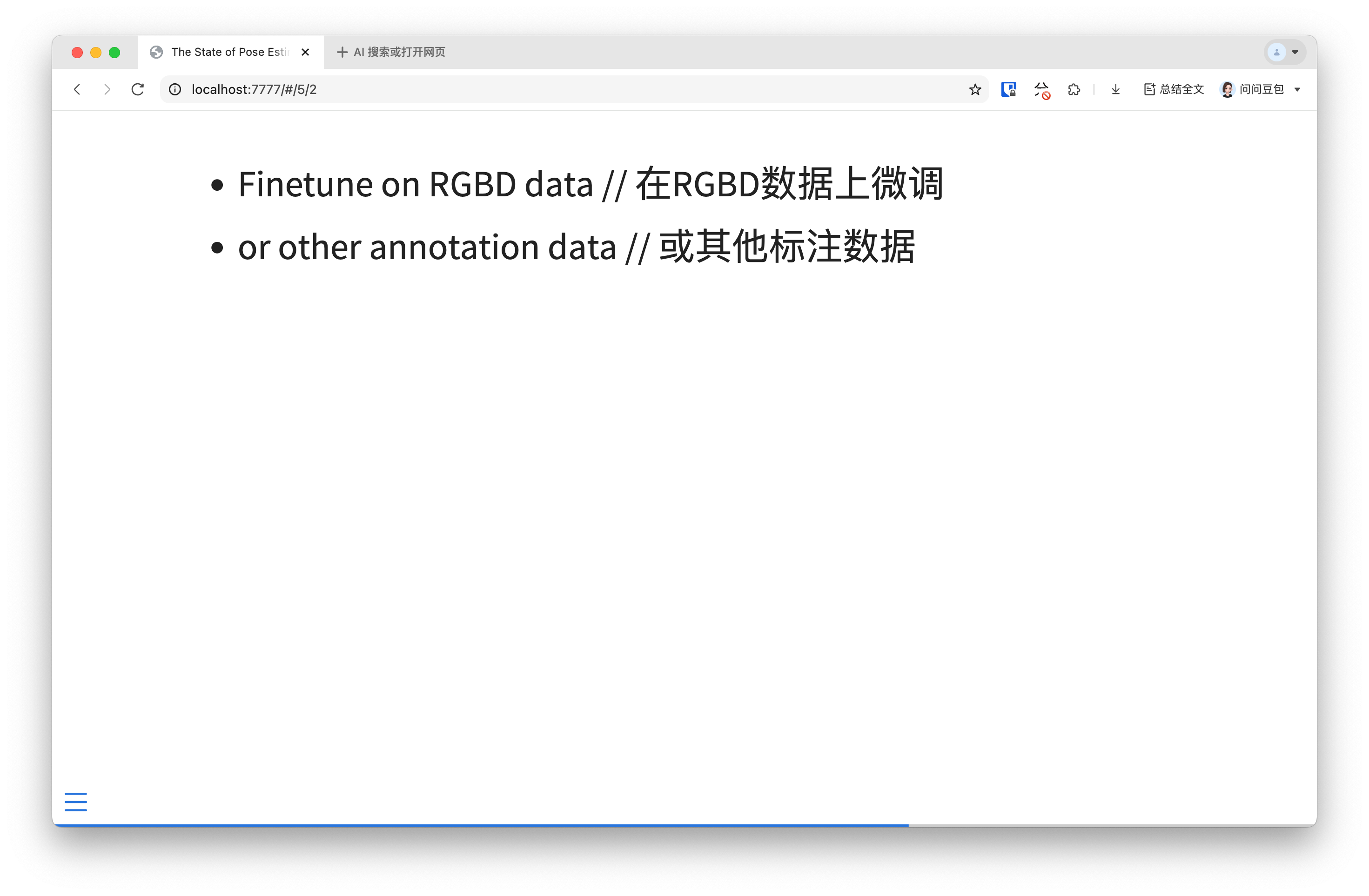
Given the challenges, a different direction maintaining the same core theory is proposed: testing whether annotating images (with RGBD or other data) improves VLM performance on specific tasks, rather than focusing on pose annotations.
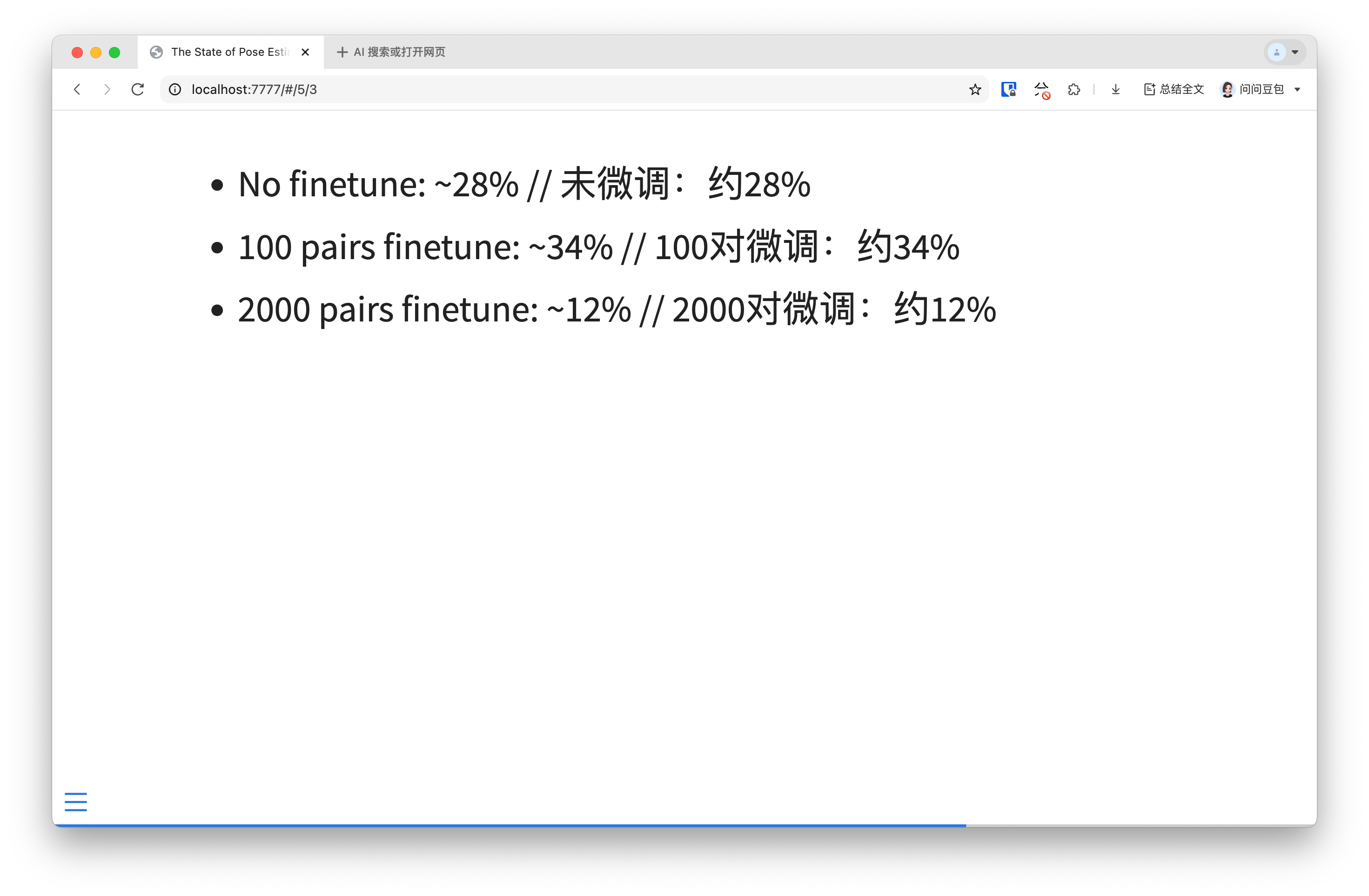
I also did a few experiments of my own, before I was assigned this project, on RGBD images to test for spatial understanding. An off-the-shelf VLM scored ~28% on a given benchmark, a 100 QnA pair finetune scored ~34%, and a 2000 QnA pair finetune scored ~12%.
My current intuition for the discrepency on the larger sample size is that while there were 2000 samples, there were only 300 unique RGBD images. This is contrary to the 100 QnA pair set which had 100 unique images. The suggests diversity is indeed important, as I pointed out earlier in my presentation.
Benefits a switching approaches is quicker iteration.
This new direction enables quicker iteration, allowing me to try more ideas out. I had set up a pipeline in which I was able to conduct those 3 prior benchmarks in a couple of days. With quicker iteration, I was able to already test for diversity. With quicker iteration, I could also test out other ideas, such as: should I keep the RGB and depth images separate? should I overlay the depth image over the RGB image? does using multiple view points of a scene help increase spatial understanding?
So I am brought to my current perspective on the current state of general purpose robotics: better, more impactful directions exist. Directions that have small steps, but allow for interesting, quick iterations and explorations.
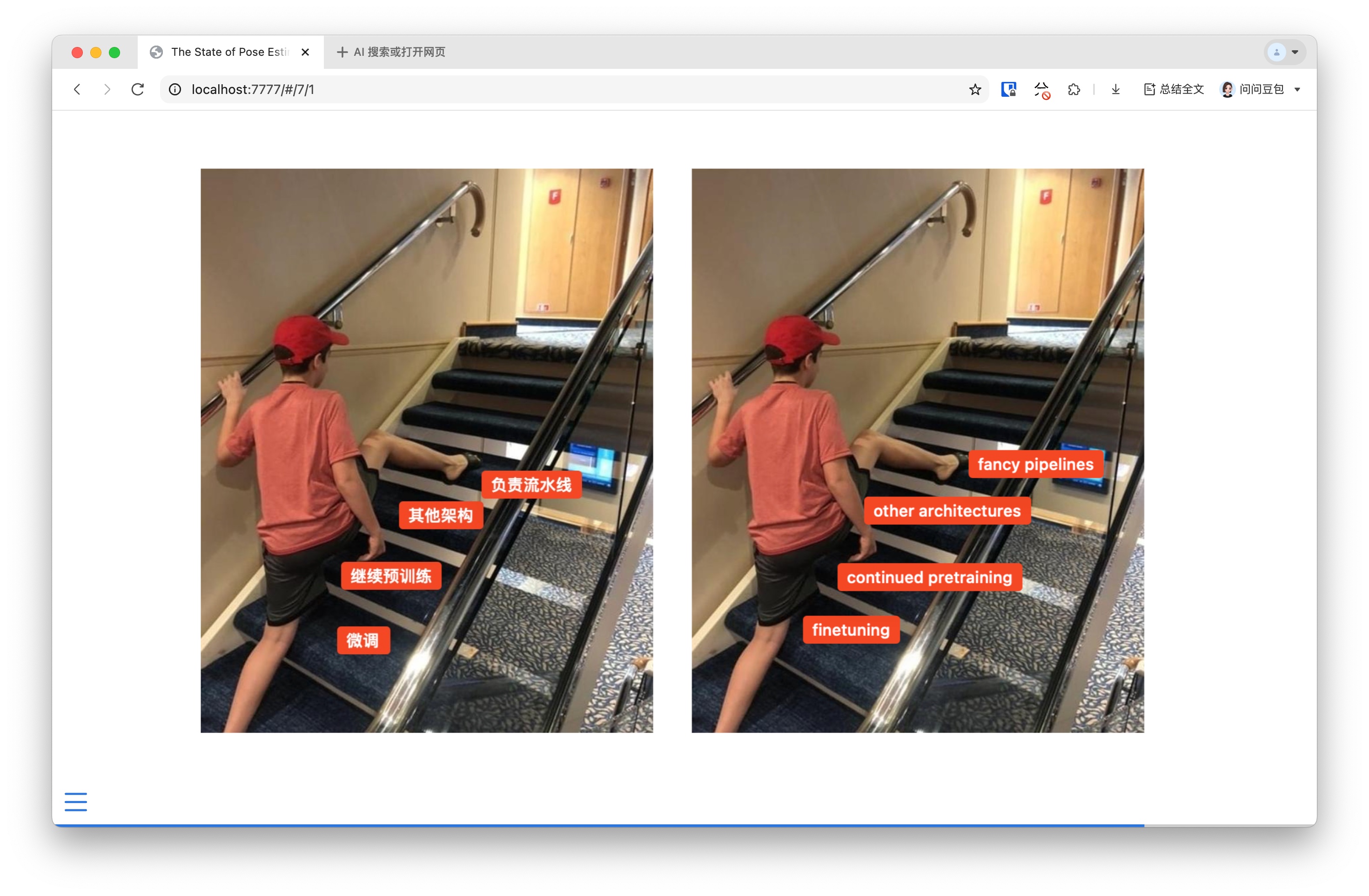
This is how I currently see the field. I see to many papers and people jumping to fancy pipelines, rather than iterating on the core pieces that underpin those fancy pipelines.
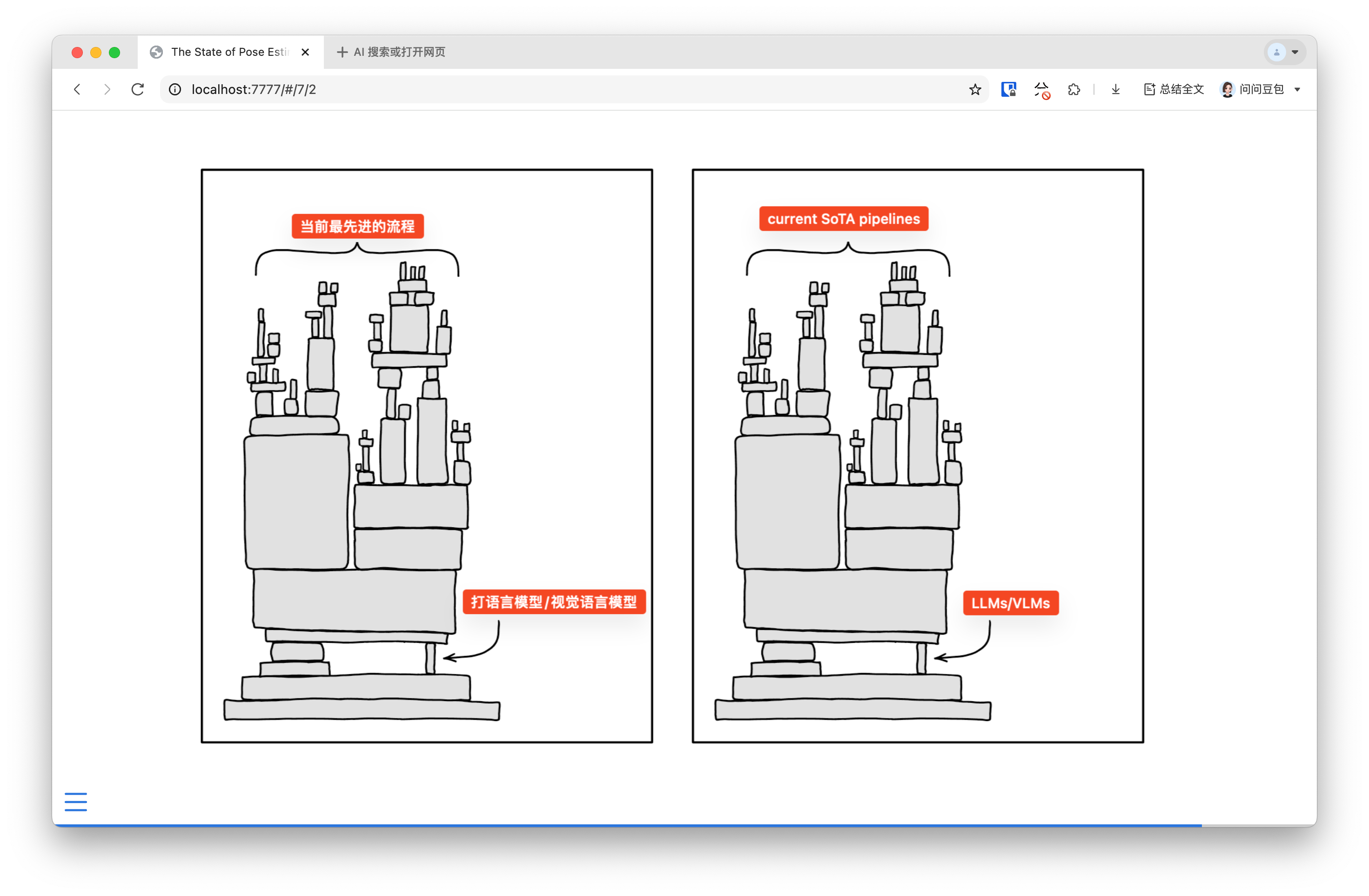
I’m surprised that the primary reason that these general purpose pipelines use VLMs for suck at the very specific reason. (I know this meme doesn’t match the original intent of the xkcd meme, but it appeared in my mind.)
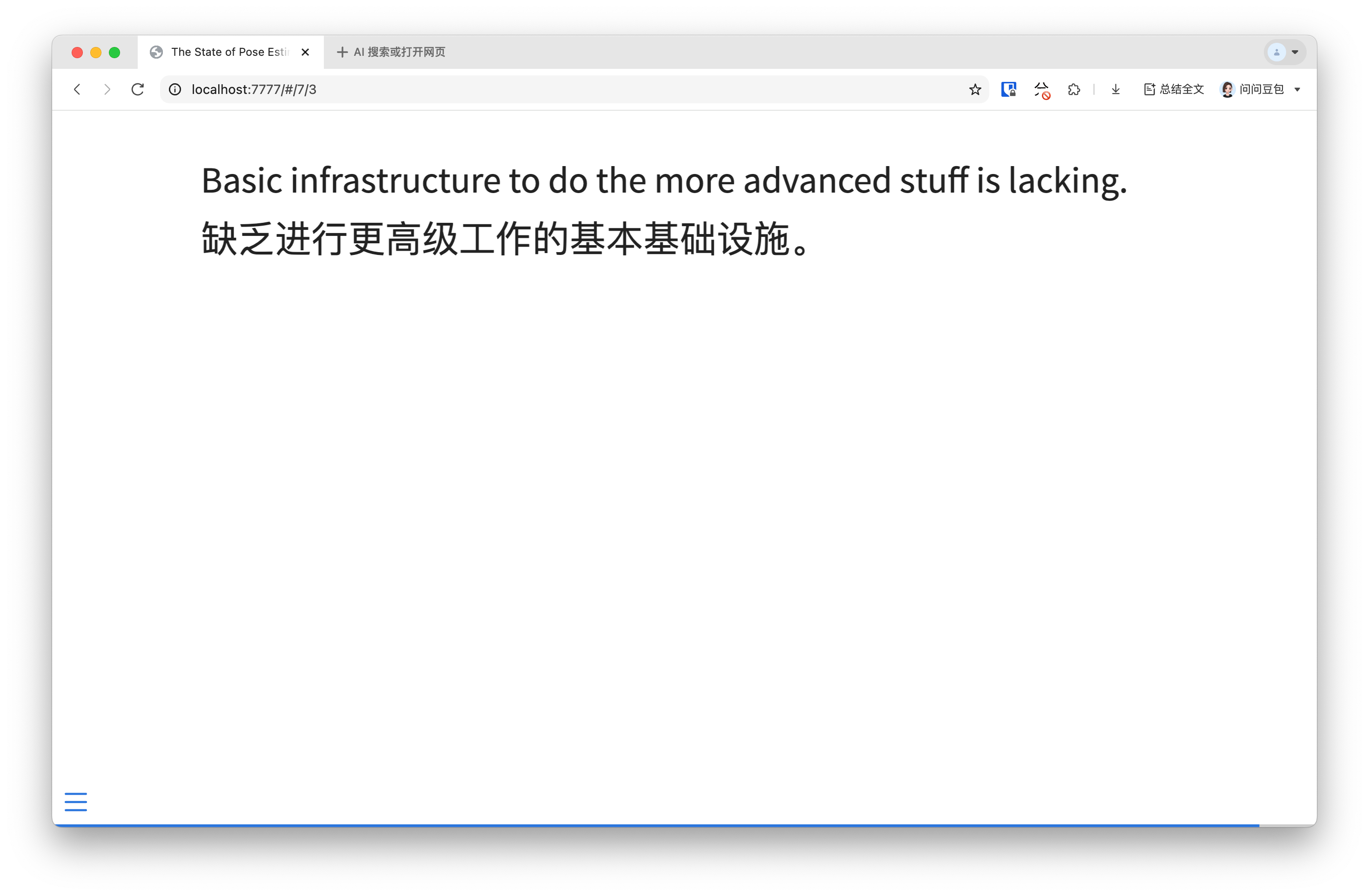
The field seems to be jumping to complex pipeline integrations rather than conducting small, meaningful iteration experiments. There’s a lack of basic infrastructure for quick experimentation, such as pose estimation models being problematic. Without these basic components and pieces being ironed out, the more interesting directions cannot be explored.
Better directions exist that focus on fundamental improvements through systematic testing rather than complex integrations.
Closing Words
As I annotated this presention, it just occured to me: overlay pose annotations on videos perhaps might not be needed at all. Current vision models and VLMs can pick out objects in images without the need for, say, a bounding box and label around the object in question. So perhaps, what needs to be done is that, perhaps, QnA pairs are created in a way that allows for the VLM to learn the concept of spaces, depth, poses, etc. The answer describes the manipulation of the object, the change in pose of the object, and so on.
If you have any comments, questions, suggestions, feedback, criticisms, or corrections, please do post them down in the comment section below!